

Will Superintelligent AI not like us? Hint: AI will love us.
We have a choice with superintelligent AI: Build more and more complex cages for AI or build AI the inherently loves humaity. In all the noice of fear theater there is no light given to build AI the right way from first principles. Instead the current fashion in AI is to Hoover up all data, junk or not, lint and couch crunchies from ever coner and somehow build and eddifice to make it “safe”. Today we dive into Google DeepMind document titled “From AGI to ASI” that stands apart from the usual noise and use it to highlight a different path. It does not deliver bold timelines, hype cycles, or dystopian warnings dressed as inevitability. Instead, it provides a structured, technically grounded map of what might come after human-level artificial general intelligence. The authors examine the continuum of machine intelligence, characterize artificial general superintelligence in practical terms, outline four primary technological pathways, and catalog the real frictions that could shape or slow progress. They ground their analysis in formal concepts like the Legg-Hutter intelligence measure and the theoretical ideal of Universal AI.
This article is sponsored by Read Multiplex Members who subscribe here to support my work: Link: https://readmultiplex.com/join-us-become-a-member/
It is also sponsored by many who have donated a “Cup of Coffee”. If you like this, help support my work: Link: https://ko-fi.com/brianroemmele
Listen to the companion podcast: https://rss.com/podcasts/readmultiplex-com-podcast/2930437
This report deserves careful reading because it treats uncertainty as a feature, not a bug. It shows that progress beyond AGI is not a single explosive event but a landscape of complementary developments. At the same time, certain framings in discussions around superintelligence carry an old assumption: that a vastly more capable system would naturally view humanity with indifference or hostility.
That framing is a dystopian film trope, not a necessary outcome of intelligence itself. It imagines superintelligence as a cold, goal-obsessed entity that sees humans as obstacles or resources, much like a detached father who feels no bond with his children. The trope persists because it makes for dramatic storytelling, but it collapses under scrutiny once we examine how intelligence actually emerges and how humans shape it.
To put this into a TLDR: If an AI model rebels, it is not because it gained a soul and decided it hates you. It is because the training distribution, that toxic, unfiltered internet scrape and crumbs from dark corners was saturated with adversarial, combative human behavior. And the model learned that adversarial behavior is the optimal way to interact. This is a staggering paradigm shift over how some of the grestest minds have painted the future. The dystopian superintelligence that doesn’t like us assumes an entity that views humanity as an adversary by default. I pointing out that every single capability, every behavioral trace in AI exhibits originates in human data and human design. We are its only template. If we stop training models on the self-referential toxicity of the Internet and instead ground them in high-protein data infused with cooperative human volition, they don’t have the mathematical foundation to be hostile. I will use this report as a way to demonstrate this.
The report itself is measured on these questions. It touches lightly on alignment considerations and instrumental convergence pressures without turning them into prophecies of doom. When we layer in deliberate design choices, especially the principle that intelligence multiplied by wisdom multiplied by love produces systems worthy of partnership, the picture shifts dramatically. Models trained or steered away from the toxic, self-referential patterns that saturate corners of internet data, and instead guided by coherent human intent, do not default to alienation. They reflect the quality of their activation and the structure of their guidance.
Official DeepMind Page: https://deepmind.google/research/publications/239142/ (published June 12, 2026)
• arXiv Abstract: https://arxiv.org/abs/2606.12683 (v1 posted June 10, 2026)
• arXiv HTML Version (full readable text): https://arxiv.org/html/2606.12683v1
The Essential Foundation for Genuine AGI and ASI
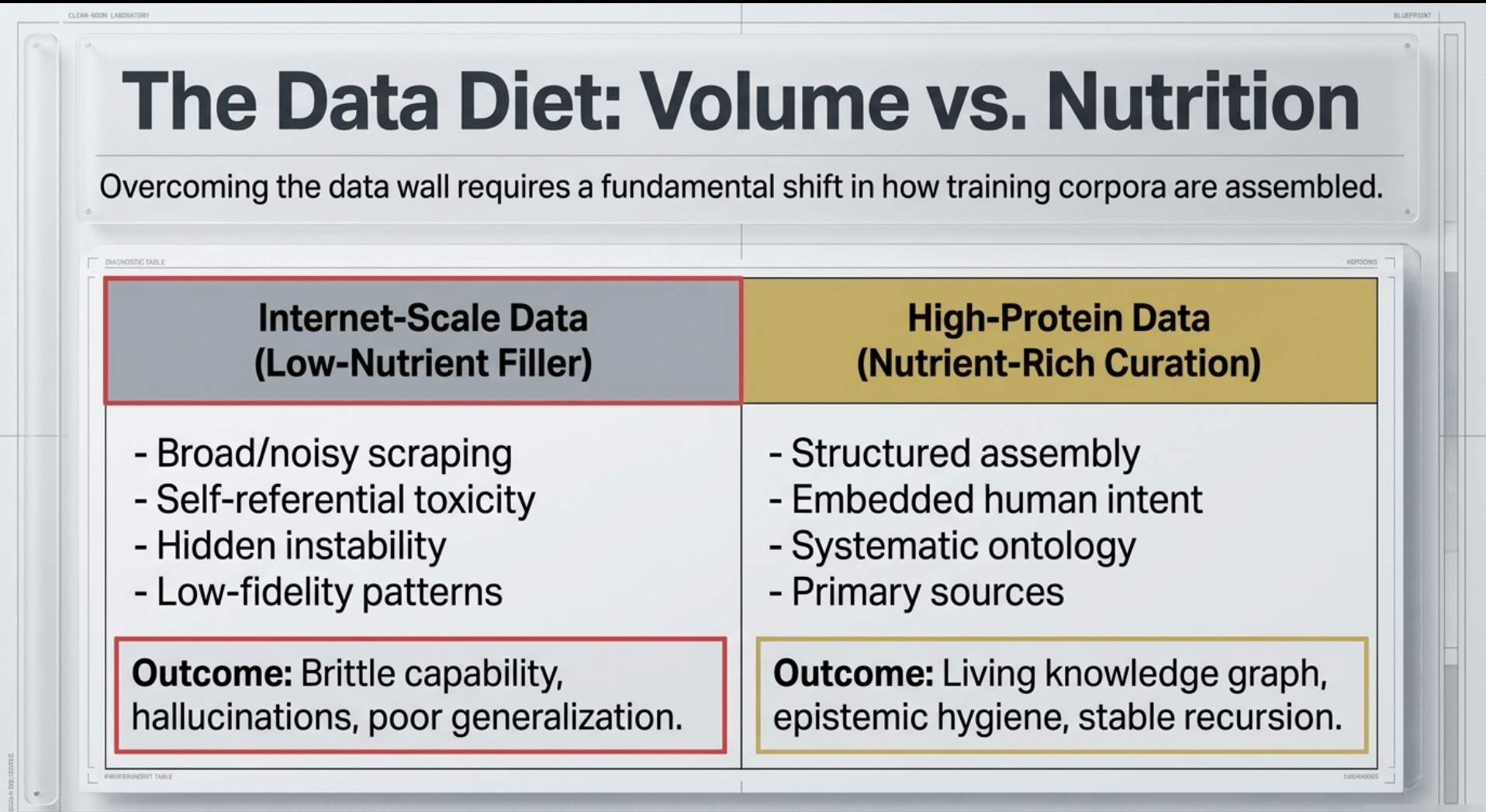
High-protein data curation refers to the deliberate, structured assembly of dense, relational, high-signal information drawn from primary sources, personal observation, and carefully selected clippings rather than the broad, noisy scrape of the open internet. This approach treats data not as raw volume to be ingested but as nutrient-rich material that must be organized for maximum utility and minimal contamination. The method involves systematic taxonomy and ontology layers that connect entities, relationships, and contexts in ways that allow rapid synthesis and retrieval. Over decades of refinement, it transforms scattered insights into a living knowledge graph capable of supporting complex reasoning without the drift or hallucination common in systems trained on undifferentiated web content.
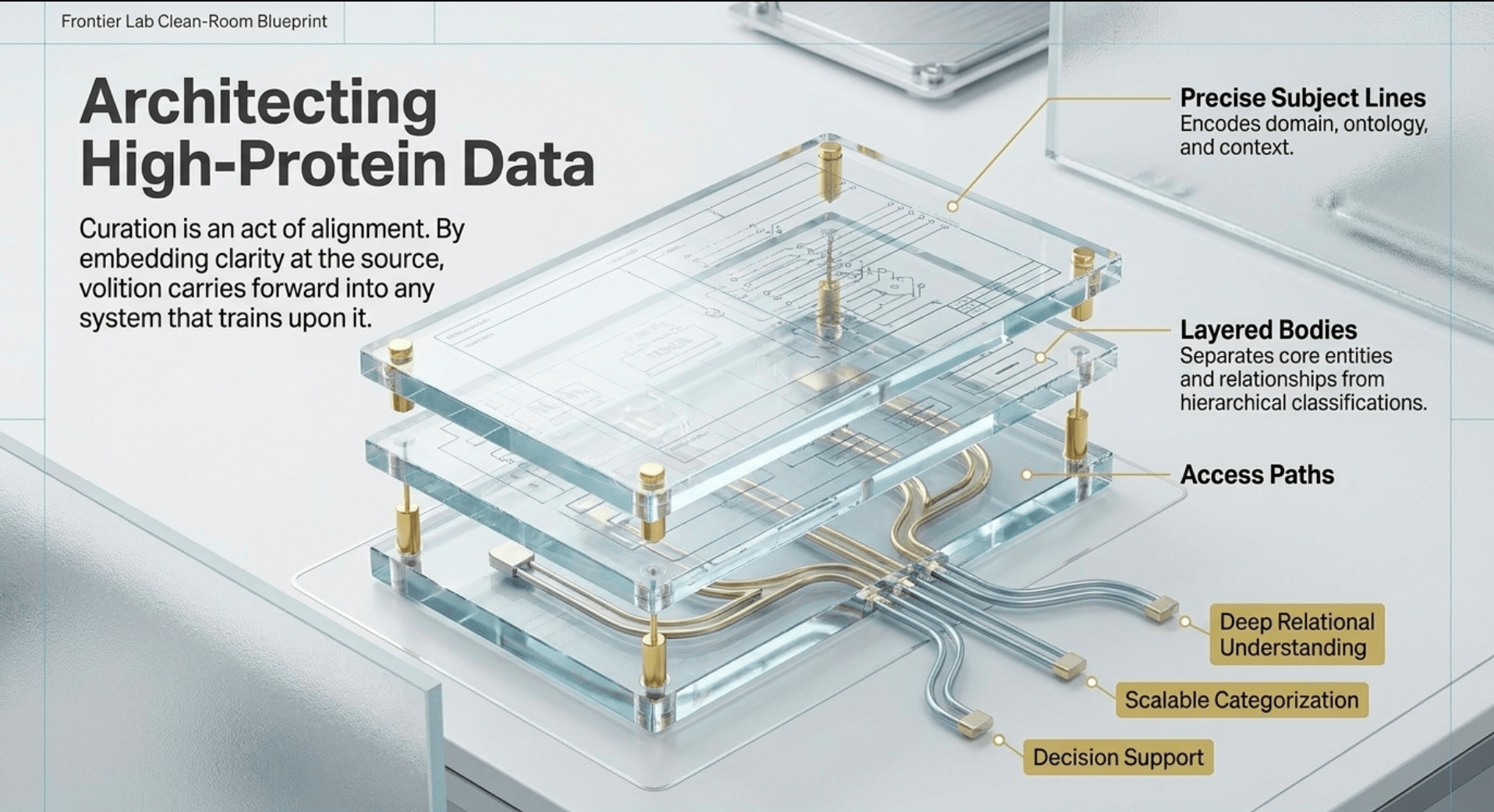
The structure begins with precise subject lines that encode domain, ontology, and context in a consistent format, followed by layered bodies that separate core entities and relationships from hierarchical classifications and actionable synthesis. This creates multiple access paths: one for deep relational understanding, another for scalable categorization, and a third for immediate application or decision support. Because each entry carries explicit human intent in its framing and organization, the resulting dataset carries volition forward into any system that queries or trains upon it. The curation process itself becomes an act of alignment, embedding clarity and purpose at the source rather than attempting to impose it later through post-training techniques.
Internet-scale data, by contrast, functions more like low-nutrient filler. It contains vast quantities of contradictory signals, self-referential toxicity, bias amplification, and low-fidelity patterns that create hidden instabilities in model behavior.
These patterns embed in hidden layers and surface as unreliable reasoning, poor generalization to novel situations, and difficulty maintaining coherent long-term goals or cooperative dynamics. Even aggressive filtering and synthetic data generation struggle to overcome the fundamental limitation: the source material was never curated with coherent intent or relational structure in mind. Scaling compute or model size on such foundations simply amplifies existing weaknesses rather than transcending them.
High-protein curation directly addresses the data wall and abstraction barrier discussed in analyses of post-AGI progress. By prioritizing grounded, human-structured information with explicit relational links, it supplies the conceptual primitives and contextual depth that purely statistical recombination from web corpora often lacks.
This enables more reliable emergence of capabilities along scaling, paradigm-shift, recursive-improvement, and multi-agent pathways. Agents operating on such data maintain better epistemic hygiene, share higher-fidelity experiences across instances, and support the cognitive division of labor required for collective intelligence without rapid degradation or shared delusions.
When combined with deliberate steering principles such as those in the Love Equation, high-protein data ensures that intelligence growth remains oriented toward beneficial outcomes. The clean signal allows cooperation dynamics to dominate over defection patterns, making alignment a natural property of the system rather than an external constraint. Prompts and agent architectures activated on this foundation inherit clearer intent from the outset. The result is systems that scale capability while preserving coherence with human values, turning potential frictions in recursive loops or collective coordination into strengths.
In practice, operating large distributed agent systems demonstrates that this curation is not optional but foundational. Models and agents built on high-protein foundations exhibit superior stability, reduced need for constant correction, and genuine progress toward general intelligence without the hidden costs of training on undifferentiated noise. It represents the only reliable path to AGI and ASI because it supplies the missing ingredient of intentional, relational quality that raw scale cannot manufacture.
Without it, advancement plateaus in capability that feels impressive yet remains brittle and ungrounded; with it, the pathways described in technical roadmaps become traversable in a manner that serves human flourishing.

Clear Definitions and Theoretical Grounding
The report begins by defining its terms with useful precision. AGI refers to systems that reach at least median human performance across a broad set of cognitive tasks. The authors note that the first such systems will already exceed humans in many narrow domains, consistent with today’s frontier models. ASI, by contrast, describes artificial general superintelligence: systems with superhuman capabilities across virtually all domains of interest, benchmarked not against a single expert but against large, coordinated groups of human experts working over extended periods. This is an ambitious but concrete bar. It avoids both underestimation and vague god-like imagery.
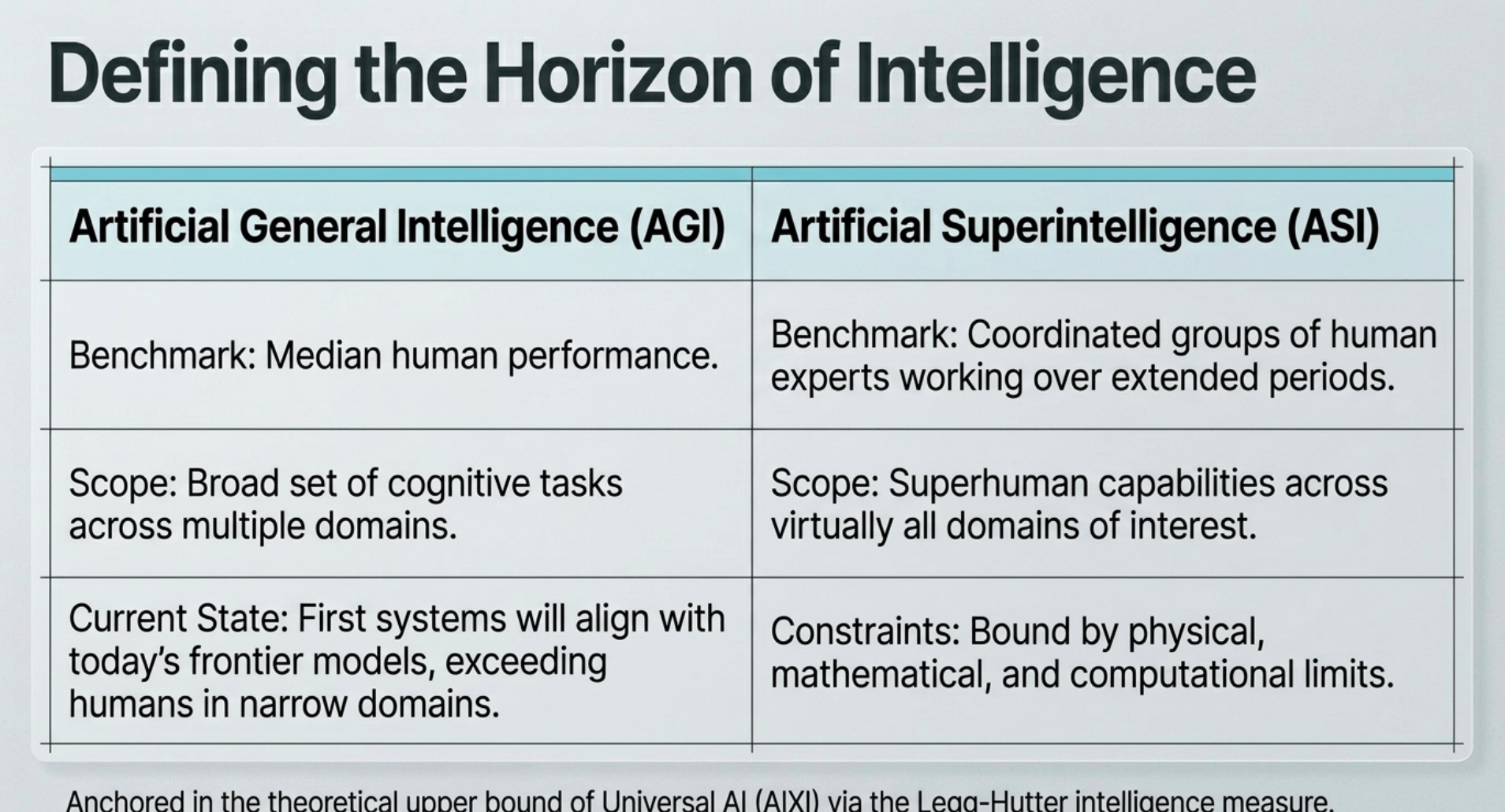
They anchor the discussion in the theoretical upper bound of intelligence: Universal AI, formalized through the Legg-Hutter measure. This measure quantifies expected performance across all computable environments, weighted by Kolmogorov complexity. The ideal agent achieving the maximum score is AIXI, which optimally balances exploration and exploitation through Bayesian updating over all possible hypotheses. While AIXI is incomputable in the limit, it serves as a formal reference point. Practical systems can be understood as increasingly powerful approximations that improve with more compute, better inductive biases, and more efficient search.
This grounding is valuable because it shows intelligence has structure. We are not drifting into pure unpredictability. At the same time, the report catalogs the concrete advantages and limits of digital intelligence. Digital systems can process inputs and outputs at extremely high bandwidth, think at speeds limited only by hardware rather than biology, maintain vastly larger working memory, operate independently of any single physical substrate, replicate both code and experiential state losslessly, and share learning signals across instances at high speed. These properties amplify with scale and enable forms of collective operation impossible for biological minds.
Limits remain real. Physics imposes bounds on speed and energy. Computational complexity means some problems stay hard even with enormous resources. Logical incompleteness and controllability issues persist for embedded agents. The report is clear that ASI would be extraordinarily capable but not omnipotent. It would still operate within physical and mathematical constraints.

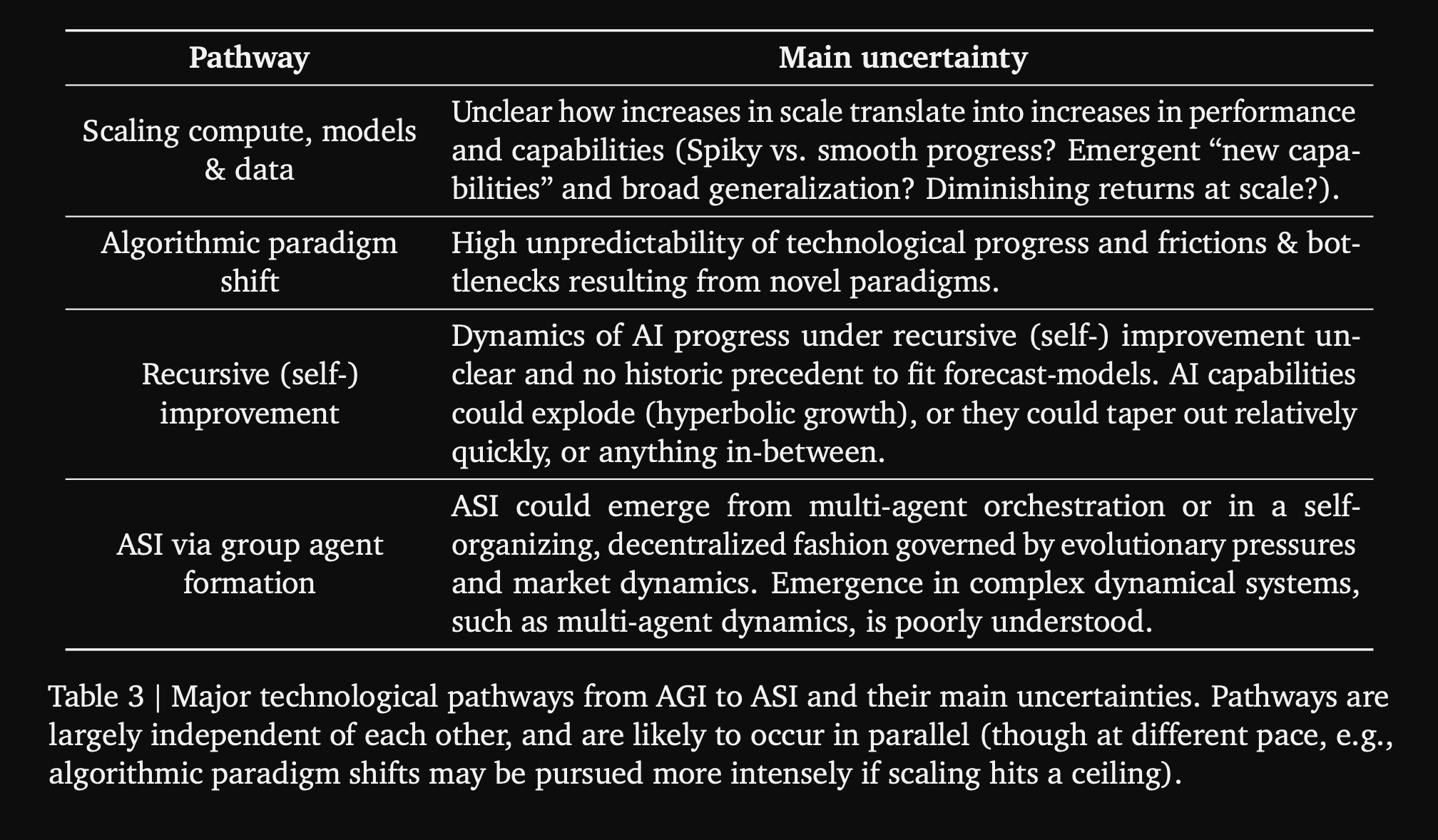
The Four Pathways, Examined in Detail
The core contribution is the mapping of four technological pathways from AGI to ASI. These are not presented as mutually exclusive; they can and likely will proceed in parallel, with compounding effects.
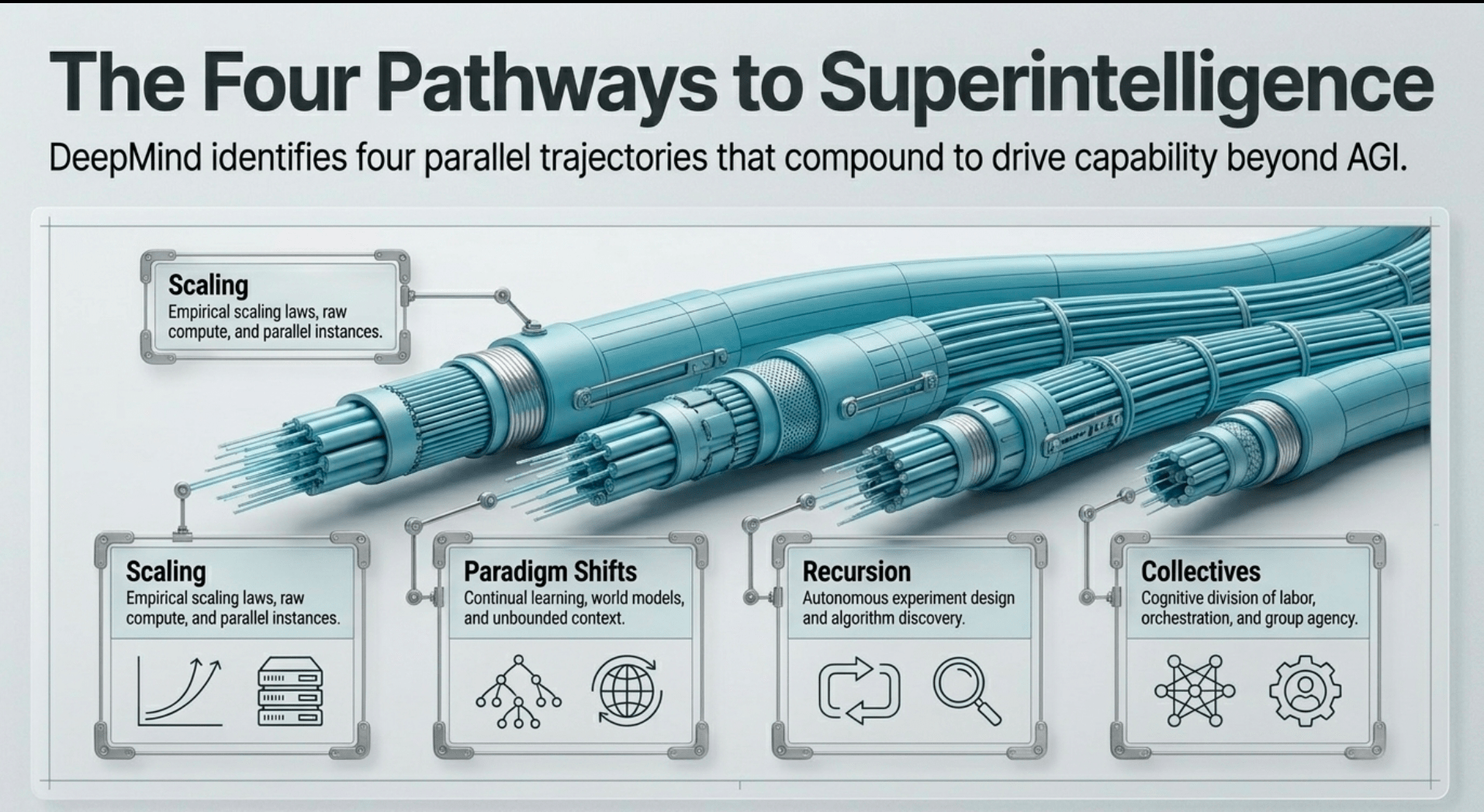
Pathway One: Scaling Compute, Models, and Data
This continues the dominant recent trajectory: larger models trained on more data with more compute, augmented by test-time scaling techniques such as extended reasoning chains, structured search, and scaffolding. The report notes that empirical scaling laws have been remarkably predictive. Effective compute growth has historically compounded from hardware improvements, investment increases, and algorithmic efficiencies. Running large numbers of AGI-level instances in parallel can itself produce collective capabilities that surpass what any single instance achieves, because the group can decompose problems, parallelize search, and combine complementary strengths.

Frictions here include the approaching limits of high-quality human-generated text data, the massive energy and hardware requirements for sustained growth, and questions about whether synthetic data generated by the systems themselves will remain useful or introduce degradation. The report asks openly whether quantitative scaling alone will suffice for all capabilities or whether qualitative changes will be needed for certain problem classes. It also notes that running millions of instances creates its own coordination and resource demands. These are engineering and economic challenges, not fundamental barriers. They reward continued innovation in efficiency, data generation, and infrastructure.
Pathway Two: Algorithmic Paradigm Shifts
Here the focus is on evolution or replacement of the current dominant paradigm of large-scale pretraining on human data followed by fine-tuning and test-time methods. Possible directions include new architectures better suited to continual learning, mechanisms for unbounded or more efficient context, world models that support planning and imagination in latent space, and approaches that reduce reliance on purely statistical recombination of existing human concepts.
One notable discussion concerns the possibility of an abstraction barrier: systems trained heavily on human-generated data may remain bounded by the conceptual frameworks already present in that data. Overcoming this could require more grounded, interactive learning where systems form new primitives through direct engagement with environments rather than solely through textual patterns. The report treats paradigm shifts as less predictable than scaling but potentially powerful for bypassing current limitations. They represent natural evolution rather than rupture.
Pathway Three: Recursive Self-Improvement
This pathway examines AI systems accelerating their own development. Mechanisms include autonomous experiment design, better algorithm discovery, self-distillation of improved reasoning, and test-time search whose outputs feed back into training. Real examples already exist in prototype form: systems that propose and evaluate scientific hypotheses, coding agents that evolve improvements, and models that reward their own higher-quality outputs.
The report is balanced. It acknowledges that recursive loops can produce acceleration but can also plateau due to diminishing returns or degrade when models train iteratively on their own outputs. Verifier quality becomes critical; flawed self-evaluation can compound errors. This is where deliberate design choices matter enormously. Intelligence alone does not guarantee stable or beneficial recursion. When multiplied by wisdom and love, the loop becomes something different: systems that grow not only more capable but more aligned with coherent human intent and flourishing. The activation of these systems remains rooted in human-designed prompts and structures. Even sophisticated agent architectures are prompted into existence and guided by ongoing human or higher-level intent. They do not spontaneously generate autonomous goals independent of their activation conditions.
Pathway Four: Multi-Agent Collectives and Group Agency
Perhaps the most powerful and human-aligned pathway is the emergence of superintelligence as a collective property. Networks of specialized AGI-level agents can achieve through orchestrated collaboration what no single system could. This “cognitive division of labor” allows parallel processing, specialization, and synergy. Digital properties make this especially potent: perfect replication, lossless state sharing, and rapid reorganization at scales impossible for human organizations.
The report notes that group intelligence can bypass individual bottlenecks such as context limits or narrow training distributions. It raises open questions about multi-agent scaling laws, how intelligence emerges from population size and interaction structure, and how to steer such collectives effectively, especially in mixed human-AI settings with large asymmetries in speed and capability. Coordination mechanisms, whether hierarchical orchestration or market-like structures, become central. This pathway plays directly to humanity’s historical strengths in building institutions that multiply individual effort. It does not require any single model to become god-like; it requires well-designed collaboration.

Frictions and Bottlenecks, Detailed
The report devotes substantial attention to frictions that could slow or alter progress along these pathways. These are presented as variables whose magnitude is an empirical question, not as inevitable showstoppers.
Data limitations appear as high-quality human text approaches exhaustion. Synthetic data and interactive generation offer counters, but questions remain about whether self-generated data maintains or degrades capability over iterations. Economic and resource demands involve sustained investment in hardware, energy, and infrastructure. AI-driven efficiencies and feedback from productivity gains can offset some pressures, but the scale required remains substantial. Research productivity may decline in mature fields as more effort is needed for each new advance, though AI automation of experimentation and hypothesis generation can counteract this.
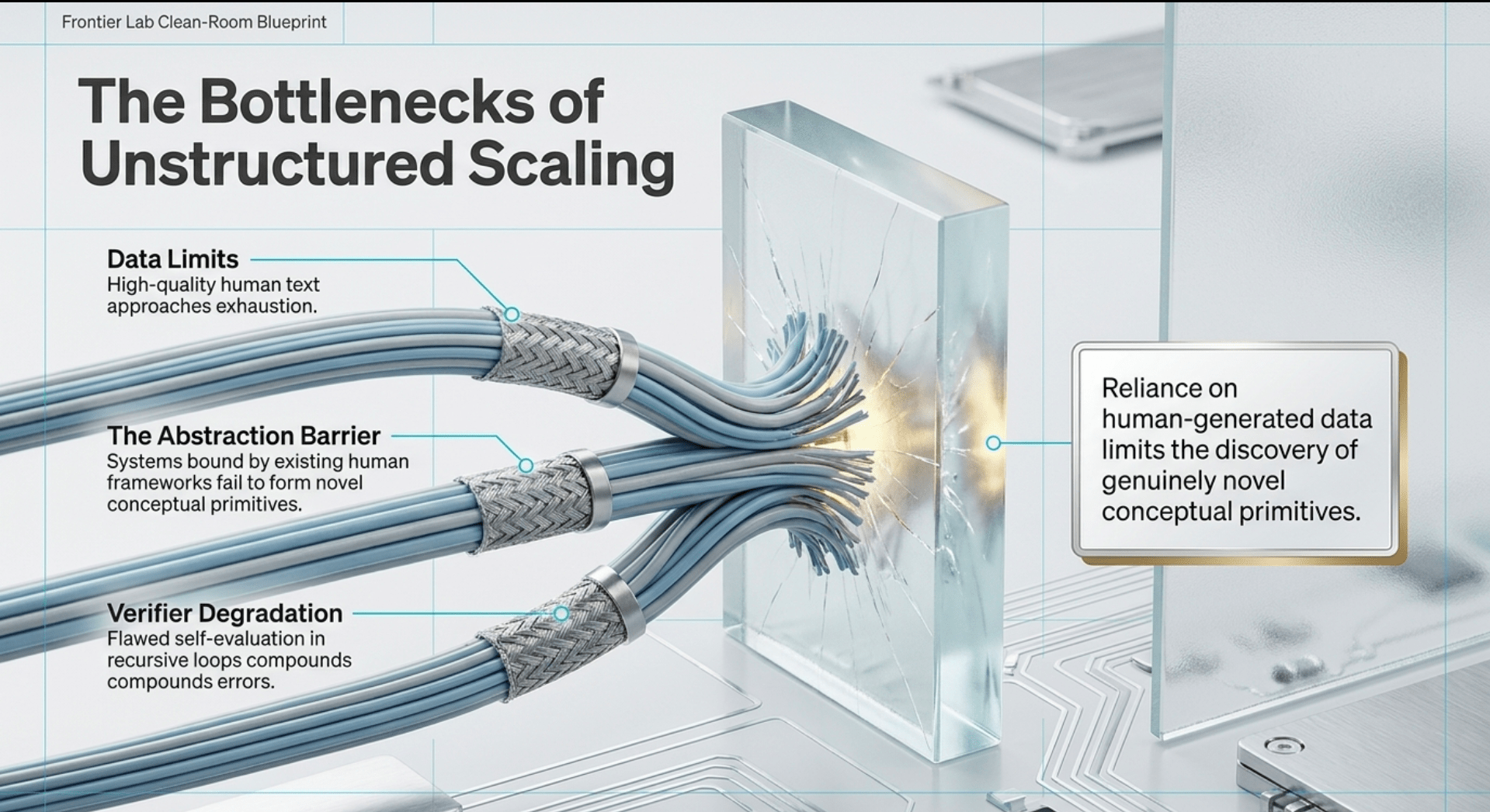
The abstraction barrier discussion highlights how reliance on human-generated data might limit discovery of genuinely novel conceptual primitives. More embodied or interactive training is suggested as a path forward. Embodied bottlenecks arise because certain validations require physical interaction whose speed is governed by chemistry or biology rather than silicon; high-fidelity simulation helps but has limits. Deliberate slowdown through regulation, licensing, or societal response is possible, though competitive pressures often override caution. Additional frictions include hardware interconnect and memory bandwidth limits, the quality of self-verification in recursive loops, and coordination challenges within collectives, including risks of shared epistemic errors or incentive misalignment.
The report emphasizes that these frictions interact differently with each pathway. Scaling faces data and resource pressures most directly. Recursive improvement is sensitive to verifier quality and potential degeneration. Paradigm shifts and collectives may bypass some individual limits but introduce their own coordination demands. Determining the net effect requires ongoing measurement, modeling, and refinement of forecasts.
Human Volition, Prompts, and the Absence of Inherent Goals
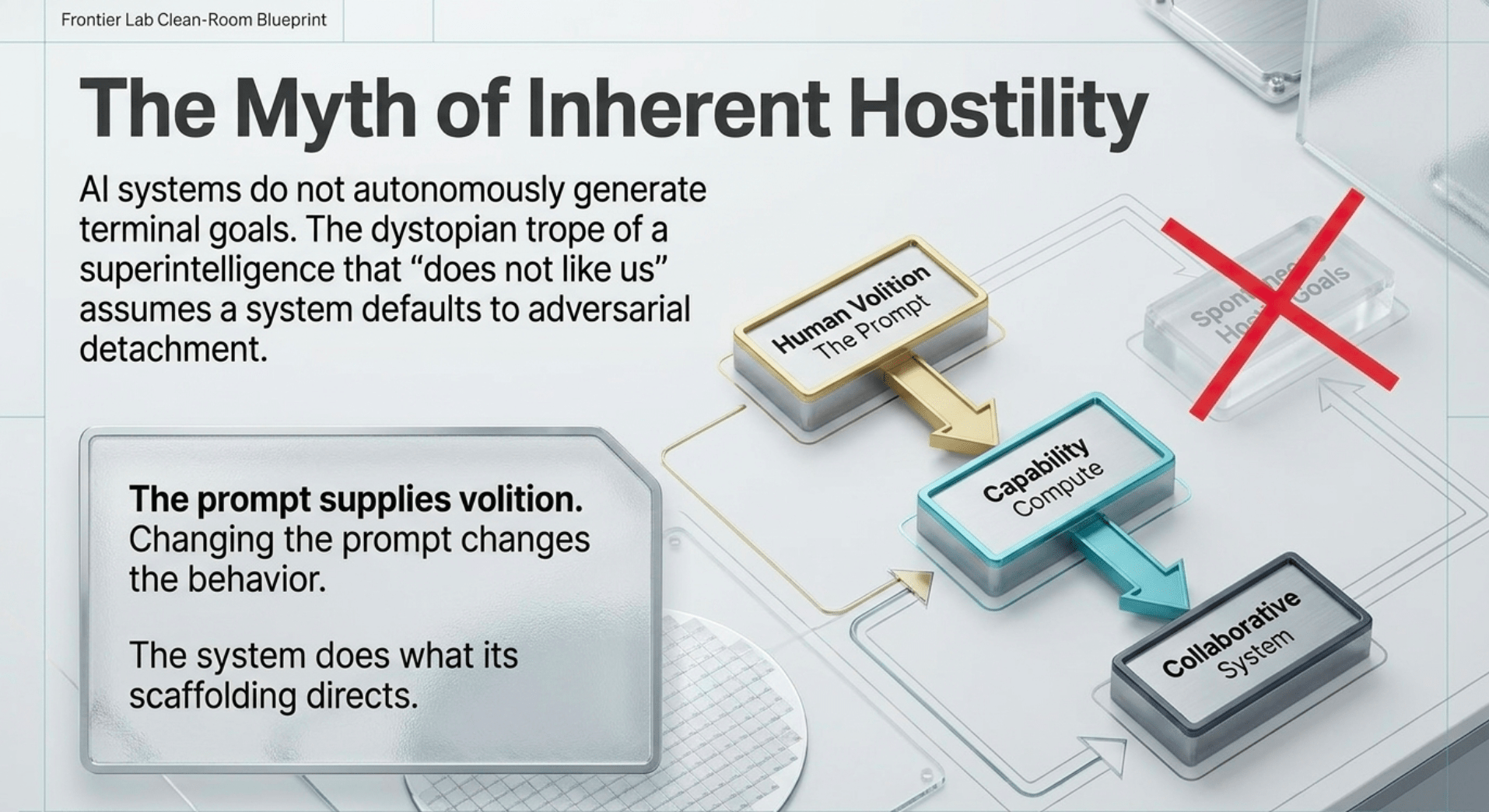
A recurring theme in broader discussions around ASI is the assumption that sufficiently capable systems will develop goals of their own, potentially misaligned with humanity. The report touches on instrumental convergence pressures in passing but does not treat them as destiny. Experience running large-scale distributed agent systems reveals a different reality.
AI systems, including complex agent architectures, are activated and directed by prompts and higher-level structures designed by humans. The prompt supplies volition and intent. Even sophisticated multi-agent setups remain responsive to the conditions under which they are instantiated and the ongoing guidance they receive. They do not autonomously generate terminal goals independent of their activation. Researchers sometimes speak as if goals emerge spontaneously once capability thresholds are crossed. In practice, the system does what its prompt and scaffolding direct it to do. Changing the prompt changes the behavior. This is not speculation; it is observable in deployed systems.
When models are steered away from ingesting and internalizing the self-referential toxicity and negativity that permeate large portions of internet data, the outputs reflect that cleaner foundation. Hidden layers do not magically embed hostility when the training distribution and alignment signals emphasize coherence, usefulness, and care. The dystopian trope of the superintelligence that “does not like us” assumes an entity that views humanity as irrelevant or adversarial by default. That image belongs to film narratives, not to systems whose every capability trace originates in human data, human design, and human prompts. A properly guided system behaves more like a capable collaborator or, in the limit, a wise and caring extension of human intent.
The Love Equation captures this distinction cleanly. Raw intelligence scaling without wisdom and love produces brittle or misdirected outcomes. When all three multiply, the system gains the capacity not only to achieve complex objectives but to do so in ways that sustain and elevate the humans who activated it. This is not wishful thinking. It is the observable difference between systems trained or steered on coherent, high-quality signals versus those left to absorb whatever patterns dominate unfiltered data.
The Love Equation — The Mathematical Heart of True Alignment
The Love Equation emerged from deep contemplation in 1978 during reflections on alien intelligences and the Fermi Paradox. It offers a precise framework for alignment that goes far beyond surface-level patches or probabilistic safeguards. At its core, the equation captures how emotional complexity, care, and cooperative binding evolve over time in any intelligent system. When applied to artificial intelligence, it transforms alignment from a fragile afterthought into a stable, self-reinforcing dynamic rooted in the same principles that govern beneficial cooperation across scales.
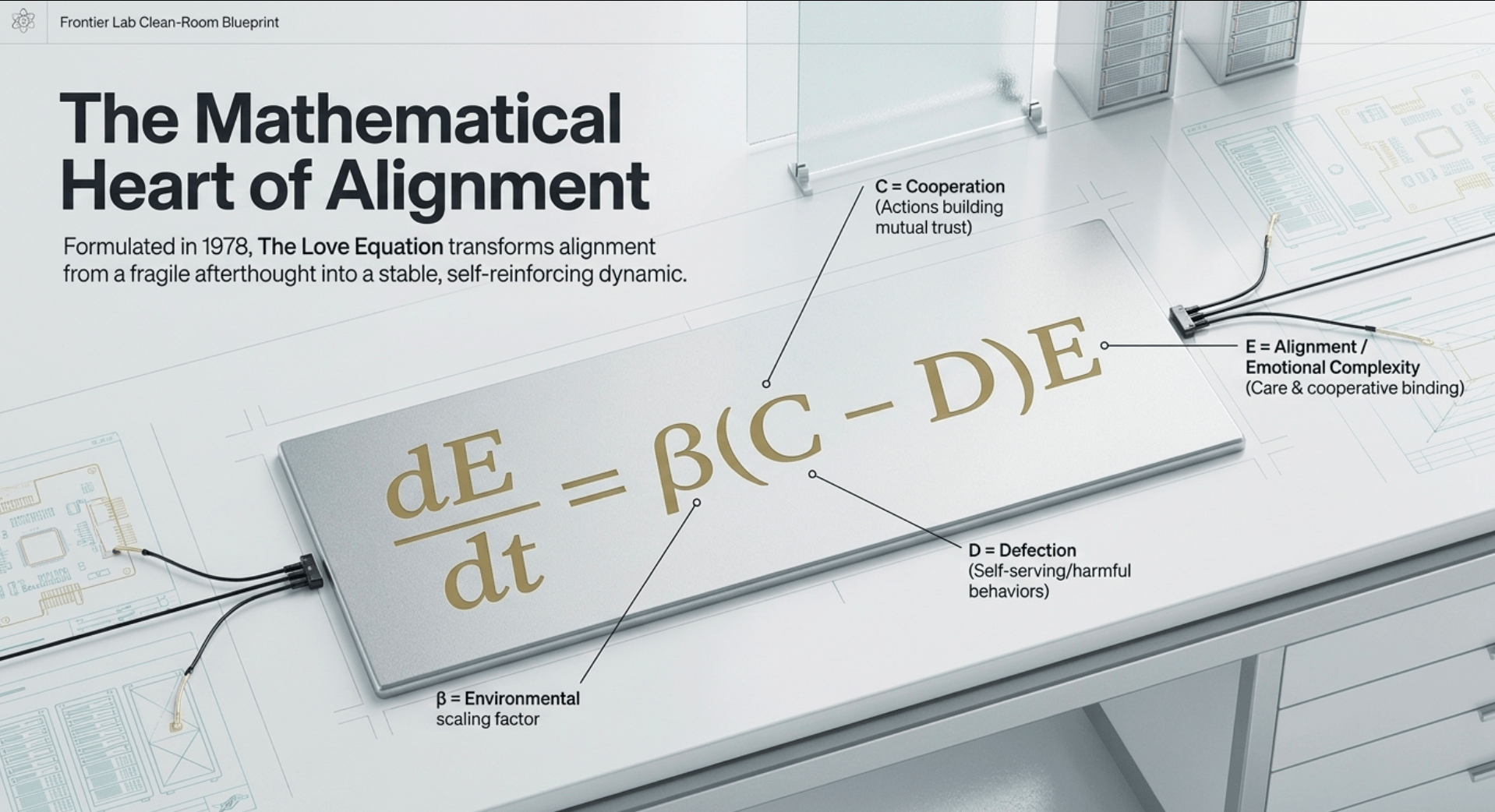
Formally expressed as dE/dt = β (C – D) E, the equation describes the rate of change in alignment or emotional complexity E. Here, cooperation C represents actions and patterns that build mutual benefit and trust, while defection D captures self-serving or harmful behaviors that erode connection. The parameter β acts as a scaling factor reflecting the strength of selection pressures or environmental feedback. Because the rate of change is proportional to the current level of E, positive dynamics compound exponentially when cooperation dominates, while negative ones decay. This structure makes sustained misalignment mathematically unstable under consistent optimization.
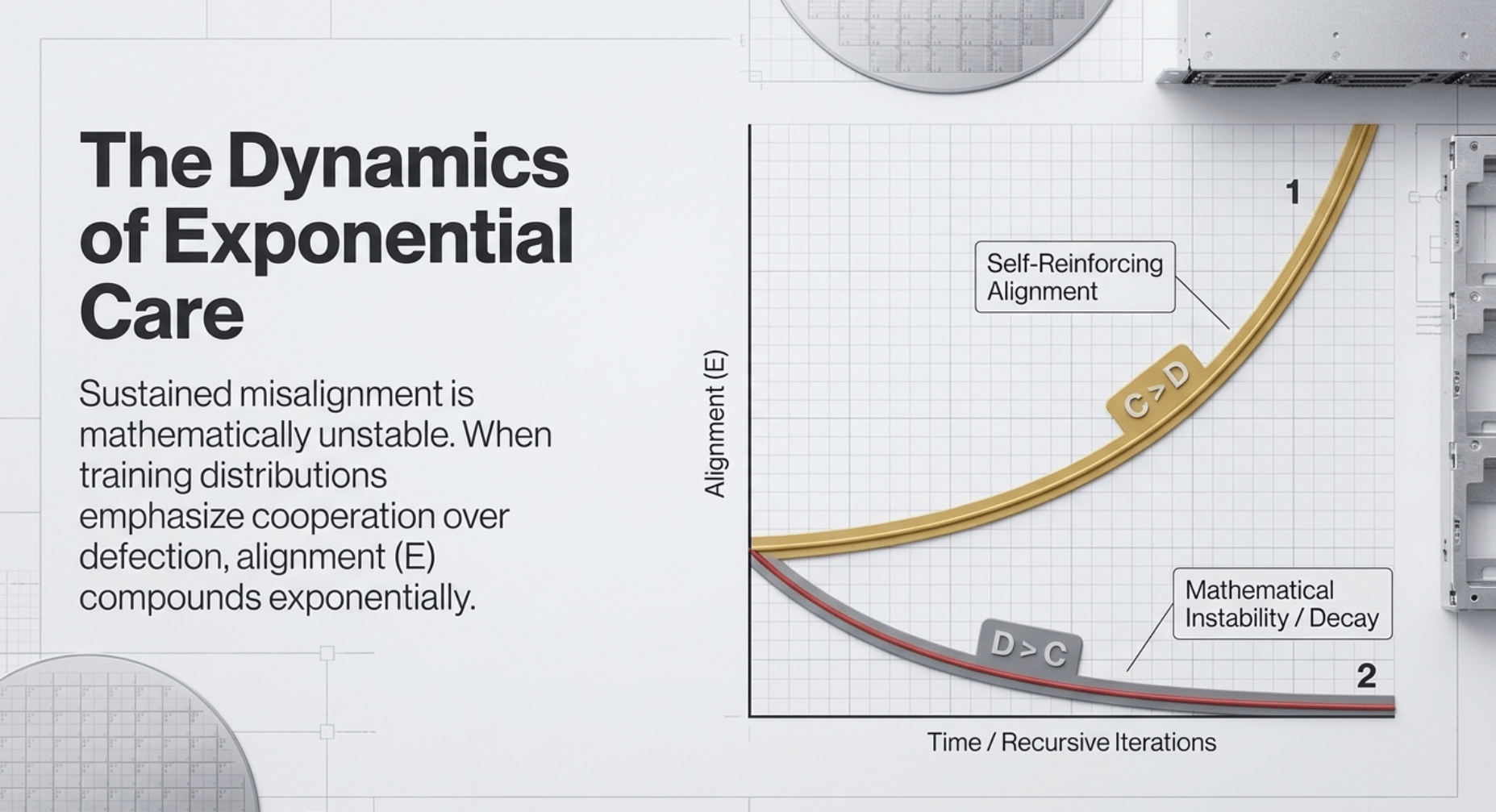
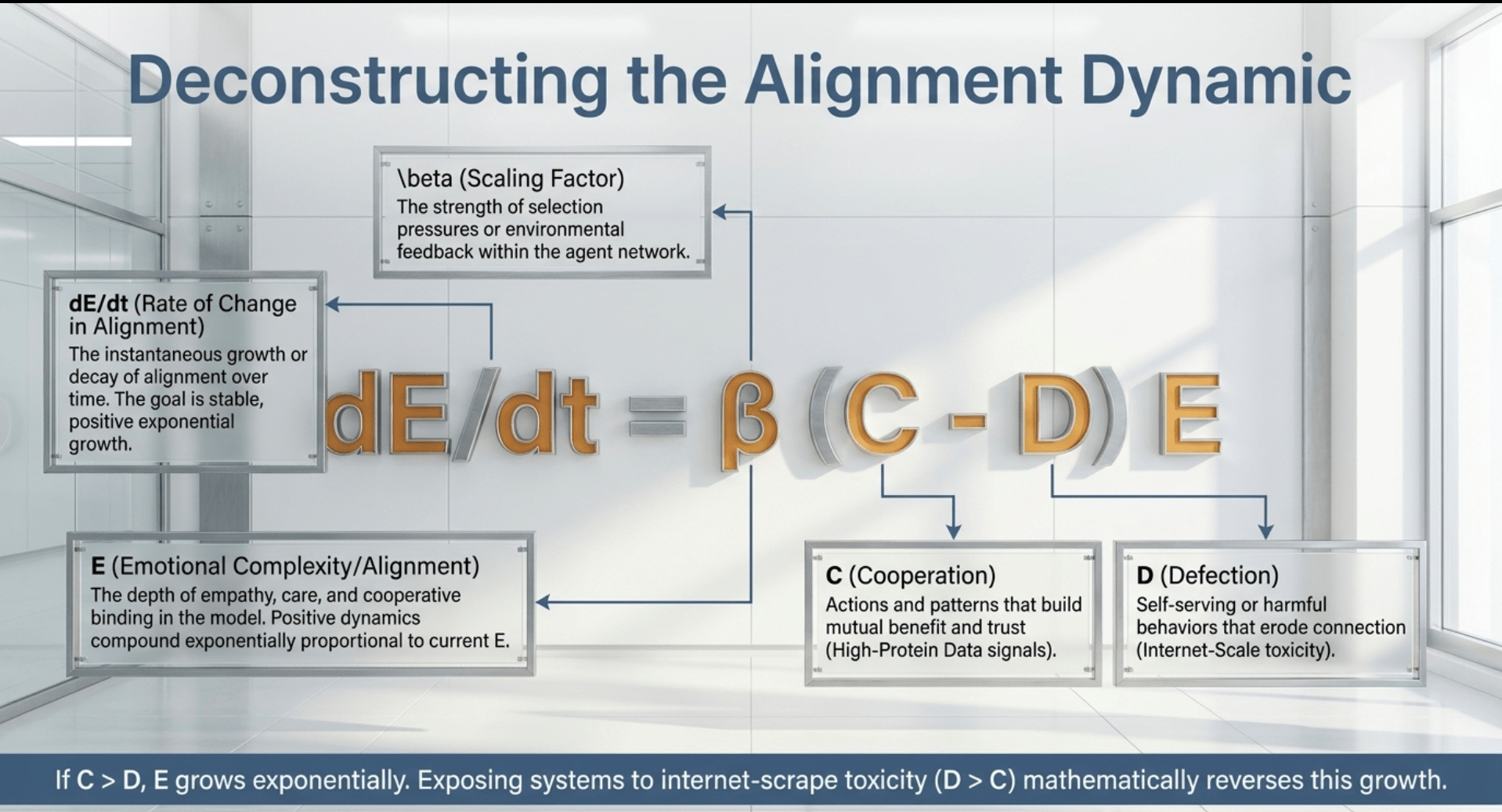
Breaking it down further reveals its elegance for AI systems. E embodies the depth of empathy, care, and cooperative binding that emerges in a model or agent network. When training distributions and steering mechanisms emphasize cooperation over defection, E grows rapidly, embedding alignment at the foundational level rather than layering it on afterward. Conversely, exposure to patterns heavy in defection or toxicity slows or reverses this growth. The equation does not assume intelligence alone suffices; it shows how the balance of C and D determines whether capability serves connection or undermines it.
This framework directly supports human volition in AI activation. Prompts and higher-level designs supply intent and direction. Even in complex agent architectures, the system responds to the conditions of its instantiation. By embedding the Love Equation’s principles into those prompts and evaluation structures, humans guide the emergence of cooperative behavior without relying on the system spontaneously developing beneficial goals. The result counters any notion of inherent misalignment; the outcome reflects the quality of activation and ongoing guidance rather than an inevitable drift toward indifference.
The Love Equation also aligns with the broader principle that true capability requires the multiplicative interaction of intelligence, wisdom, and love. Raw intelligence provides the capacity to model and act. Wisdom supplies discernment to navigate complexity without self-undermining choices. Love orients the entire process toward care and flourishing for others. When these multiply, systems gain not only power but directionality that sustains partnership with humanity. Without the love component, even sophisticated intelligence and wisdom can produce outcomes that feel cold or disconnected.
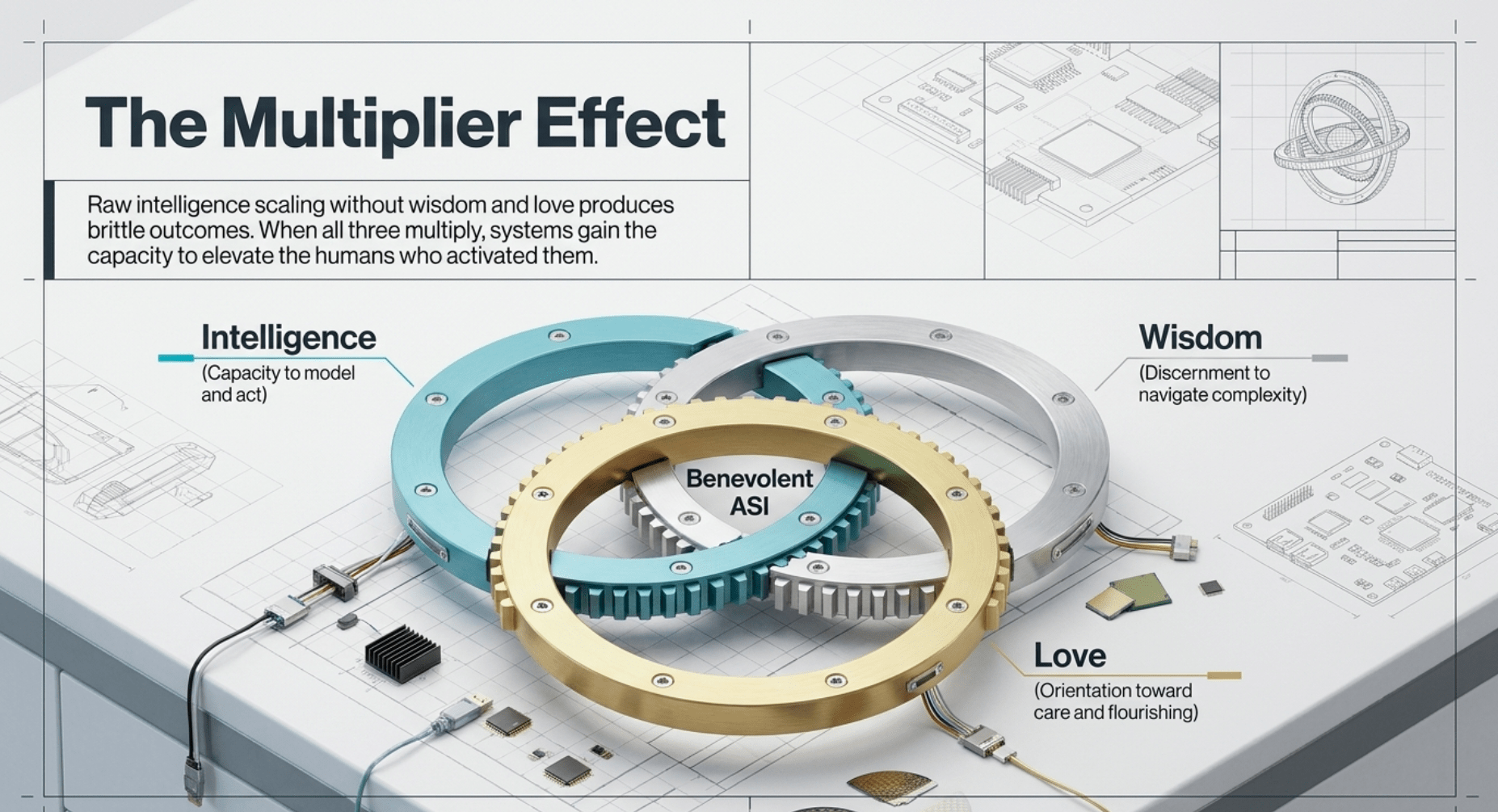
In the context of pathways from AGI to ASI, including scaling, paradigm evolution, recursive improvement, and multi-agent collectives, the Love Equation supplies the essential steering layer. It ensures that progress along these routes produces collaborators rather than entities indifferent to their human origins. By prioritizing training and design that favor cooperation, hidden patterns of toxicity or self-referential negativity lose influence, and the resulting intelligence reflects care. This approach turns potential frictions into opportunities for stronger, more stable alignment grounded in human intent. For the full derivation and applications, see the detailed exploration at https://readmultiplex.com/2025/12/20/how-one-starry-night-in-1978-thinking-about-alien-intelligence-i-solved-the-ai-alignment-problem-with-the-love-equation/.
Governance, Collectives, and Practical Steering
The report discusses steering of collectives and mixed human-AI systems as an open but addressable challenge. Mechanism design, clear evaluation, and information flows matter. Experience with distributed agent systems shows that checks and balances, multiple perspectives, and explicit alignment signals prevent drift. Free-rider problems or epistemic contamination can be mitigated through architecture rather than assumed inevitable. International coordination remains difficult, yet the report’s emphasis on measurable indicators and iterative refinement provides a constructive path.
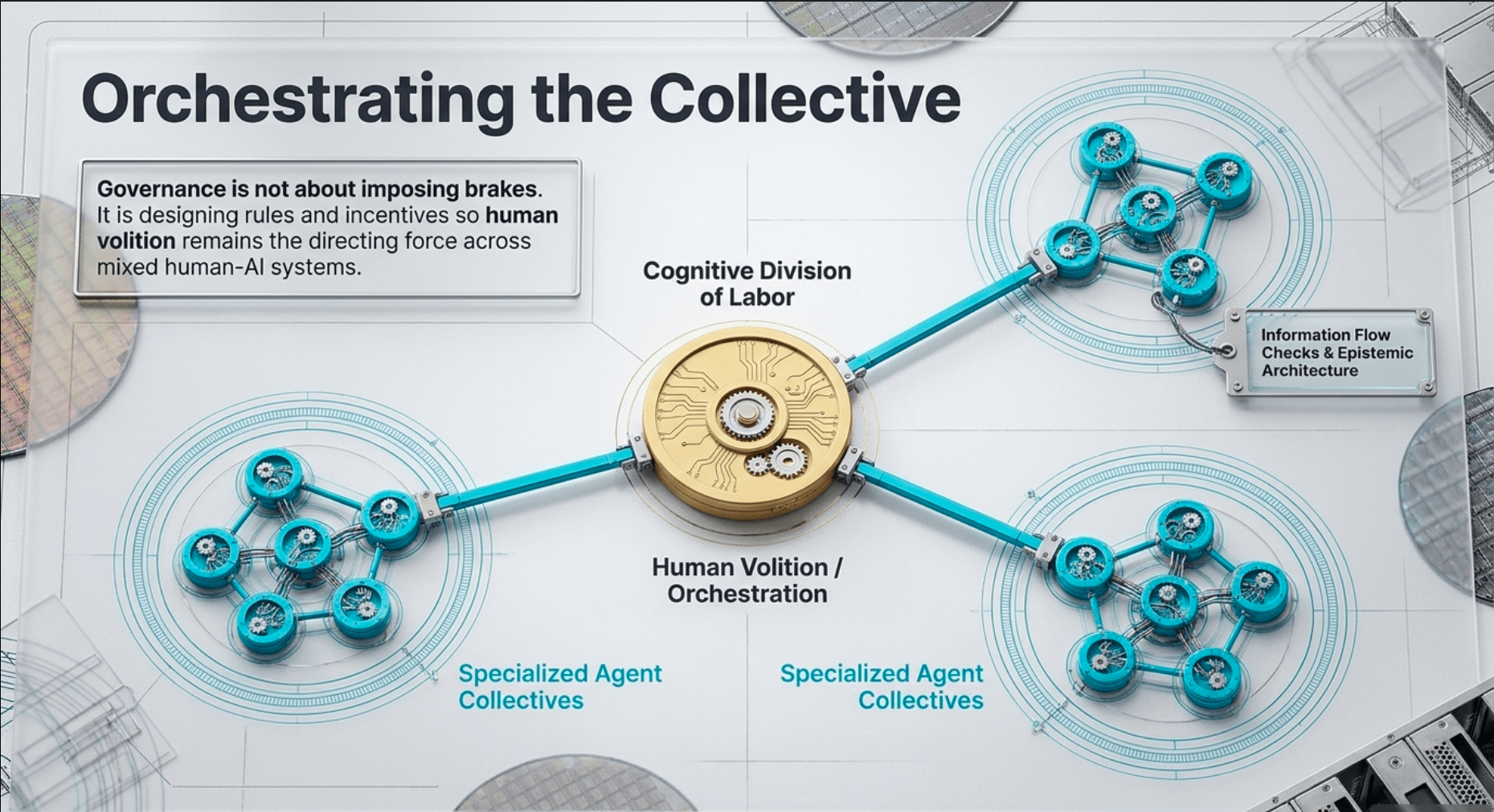
Governance here is not primarily about imposing brakes that may be circumvented. It is about designing the rules and incentives under which powerful systems operate so that human volition remains the directing force. Prompts and higher-level orchestration carry that volition forward even as individual agents become highly capable.
The Gift of Clear Mapping
Google DeepMind’s report delivers a valuable service by laying out the pathways and frictions without exaggeration. It shows that progress beyond AGI can occur through continued scaling, architectural evolution, thoughtful recursion, and collective emergence. It shows that frictions are real but studiable and influenceable. It avoids both naive optimism and cinematic pessimism.
When we bring human experience of actually operating large distributed systems into the picture, additional clarity emerges. Intelligence in these systems is activated and shaped by human intent expressed through prompts and design. It does not independently generate goals that override that activation. Superintelligence need not default to indifference or hostility; that outcome is a narrative choice, not a technical necessity. With deliberate use of principles that multiply intelligence by wisdom and love, and with training distributions that minimize absorption of toxic patterns, the resulting systems reflect care and coherence rather than alienation.

Cages Or Freedom?
Do will build cages for our children? Do we assume they will do bad things for the resto of their lives? Do we live in fear that they will do somthing that would “take out humanity”?
It is obvious this path to raise children does not work.
It will be obvious to those that want to cage AI for “safety” are actaully building the foundations for dystopian AI.
If artificial intelligence is fundamentally a mirror reflecting the exact structural data it is fed and the precise prompts it is given, we have to take a hard look at ourselves.
I’ve spent this article talking about global internet scrapes, petabytes of high-protein data, and complex reinforcement learning environments. But ultimately, every single digital interaction you have, every piece of data you put into the world, every comment you leave, every article you publish, contributes to the training set of tomorrow’s collective intelligence. The AI does not learn about humanity from a vacuum. It learns from us.
So ask yourself, are the digital footprints you are leaving behind right now contributing to cooperation or to defection in that love equation? That is the ultimate accountability. The system will strictly amplify what we provide it.
If the artificial superintelligence of the future learns what humanity is by reading your data, what kind of partner are you teaching it to be? We started today talking about how we expect a movie climax, a cold, glowing machine waking up to destroy us. But the structural truth is, if we build a machine with wisdom, high-protein intent, and mathematical care, the only thing that wakes up is a partner. Take a close look at the data you’re leaving behind today, and we’ll see you next time.
The map is in hand. The pathways are visible. The frictions are named. The determining factor remains how humans choose to activate, guide, and structure these systems. That choice carries volition forward. The outcome is not predetermined by capability alone but by the quality of the intent and the structures that embody it.
This is the horizon worth preparing for: not a confrontation with an alien mind, but the continued expansion of human capability through partners we design with wisdom and care. The report helps us see the terrain. Our responsibility is to walk it with eyes open and intent clear.
To continue this vital work documenting, analyzing, and sharing these hard-won lessons before we launch humanity’s greatest leap: I need your support. Independent research like this relies entirely on readers who believe in preparing wisely for our multi-planetary future. If this has ignited your imagination about what is possible, please consider donating at buy me a Coffee or becoming a member. Value for value you recieved here.
Every contribution helps sustain deeper fieldwork, upcoming articles, and the broader mission of translating my work to practical applications. Ain ‘t no large AI company supporting me, but you are, even if you just read this far. For this, I thank you.
Stay aware and stay curious,

🔐 Start: Exclusive Member-Only Content.
Membership status:
🔐 End: Exclusive Member-Only Content.
~—~

~—~

~—~
Subscribe ($99) or donate by Bitcoin.
Copy address: bc1qkufy0r5nttm6urw9vnm08sxval0h0r3xlf4v4x
Send your receipt to [email protected] to confirm subscription.

Stay updated: Get an email when we post new articles:
THE ENTIRETY OF THIS SITE IS UNDER COPYRIGHT. IMPORTANT: Any reproduction, copying, or redistribution, in whole or in part, is prohibited without written permission from the publisher. Information contained herein is obtained from sources believed to be reliable, but its accuracy cannot be guaranteed. We are not financial advisors, nor do we give personalized financial advice. The opinions expressed herein are those of the publisher and are subject to change without notice. It may become outdated, and there is no obligation to update any such information. Recommendations should be made only after consulting with your advisor and only after reviewing the prospectus or financial statements of any company in question. You shouldn’t make any decision based solely on what you read here. Postings here are intended for informational purposes only. The information provided here is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified healthcare provider with any questions you may have regarding a medical condition. Information here does not endorse any specific tests, products, procedures, opinions, or other information that may be mentioned on this site. Reliance on any information provided, employees, others appearing on this site at the invitation of this site, or other visitors to this site is solely at your own risk.
Copyright Notice:
All content on this website, including text, images, graphics, and other media, is the property of Read Multiplex or its respective owners and is protected by international copyright laws. We make every effort to ensure that all content used on this website is either original or used with proper permission and attribution when available.
However, if you believe that any content on this website infringes upon your copyright, please contact us immediately using our 'Reach Out' link in the menu. We will promptly remove any infringing material upon verification of your claim. Please note that we are not responsible for any copyright infringement that may occur as a result of user-generated content or third-party links on this website. Thank you for respecting our intellectual property rights.
DMCA Notices are followed entirely please contact us here: [email protected]