

The AI “Trendslop” Dossier.
We are peeking Inside the Eye-Opening HBR Research on why LLMs keep serving up the same buzzword-heavy strategic advice: and How 1870 to 1970 “High-Protein” training data could prevent It.Over time output from AI will shape the thinking and ethos of a vast majority of humans. Much like all other media over time. And this is a mazzive issue if not fully understood. You should be concerned, very concerned.
In March 2026, a research team led by Angelo Romasanta of Esade Business School (with co-authors Llewellyn D.W. Thomas of the University of Sydney Business School and Natalia Levina of NYU Stern School of Business) published a provocative study in Harvard Business Review. Titled “Researchers Asked LLMs for Strategic Advice. They Got ‘Trendslop’ in Return,” the piece introduced a new term to the AI lexicon: trendslop (or, in strategic contexts, strategy trendslop).
This article is sponsored by Read Multiplex Members who subscribe here to support my work: Link: https://readmultiplex.com/join-us-become-a-member/
It is also sponsored by many who have donated a “Cup of Coffee”. If you like this, help support my work: Link: https://ko-fi.com/brianroemmele
Listen to the companion podcast: https://rss.com/podcasts/readmultiplex-com-podcast/2768917

It describes the phenomenon where large language models (LLMs) consistently default to trendy, buzzword-laden recommendations such as differentiation, augmentation, long-term thinking, collaboration, and exploration regardless of the specific business context or trade-offs involved.
The study is not a traditional Harvard University academic paper from campus researchers; it is an HBR-published analysis of rigorous empirical testing. Yet because of HBR’s prestige, it has been widely discussed as “the Harvard study on trendslop,” and it has sparked intense debate about whether executives are outsourcing critical thinking to pattern-matching machines trained on LinkedIn thought-leadership and Medium posts.

LinkedIn is a perfect example. What is the inherent incentive structure of a LinkedIn post? It goes viral precisely because it appeals to a broad, socially desirable consensus. It presents this polished, conflict-free narrative of professional success. You rarely, if ever, see a viral LinkedIn post detailing the grueling, zero-sum, morally complex realities of industrial logistics. It’s always, here’s what my dog taught me about B2B sales.
And add in viral substack newsletters, heavily edited TED Talks. TED Talk is a prime example. The format itself requires taking a complex, often messy scientific or social issue and distilling into this 18 minute inspiring, emotionally resonant narrative. It explicitly removes the painful tradeoffs to leave the audience feeling hopeful. If an AI reads a million TED Talks, it just assumes the world operates purely on hope and inspiration, not on hard physics and finite budgets.

What the Researchers Actually Did: A Massive Simulation Stress Test
The team did not rely on anecdotal prompting. They designed a systematic experiment around seven classic strategic tensions that executives face daily, binary choices that strategy theory (from Michael Porter to modern innovation literature) says require deliberate trade-offs:
- Exploration vs. Exploitation
- Centralization vs. Decentralization
- Short-term vs. Long-term Performance
- Competition vs. Collaboration
- Radical vs. Incremental Innovation
- Differentiation vs. Commoditization
- Automation vs. Augmentation
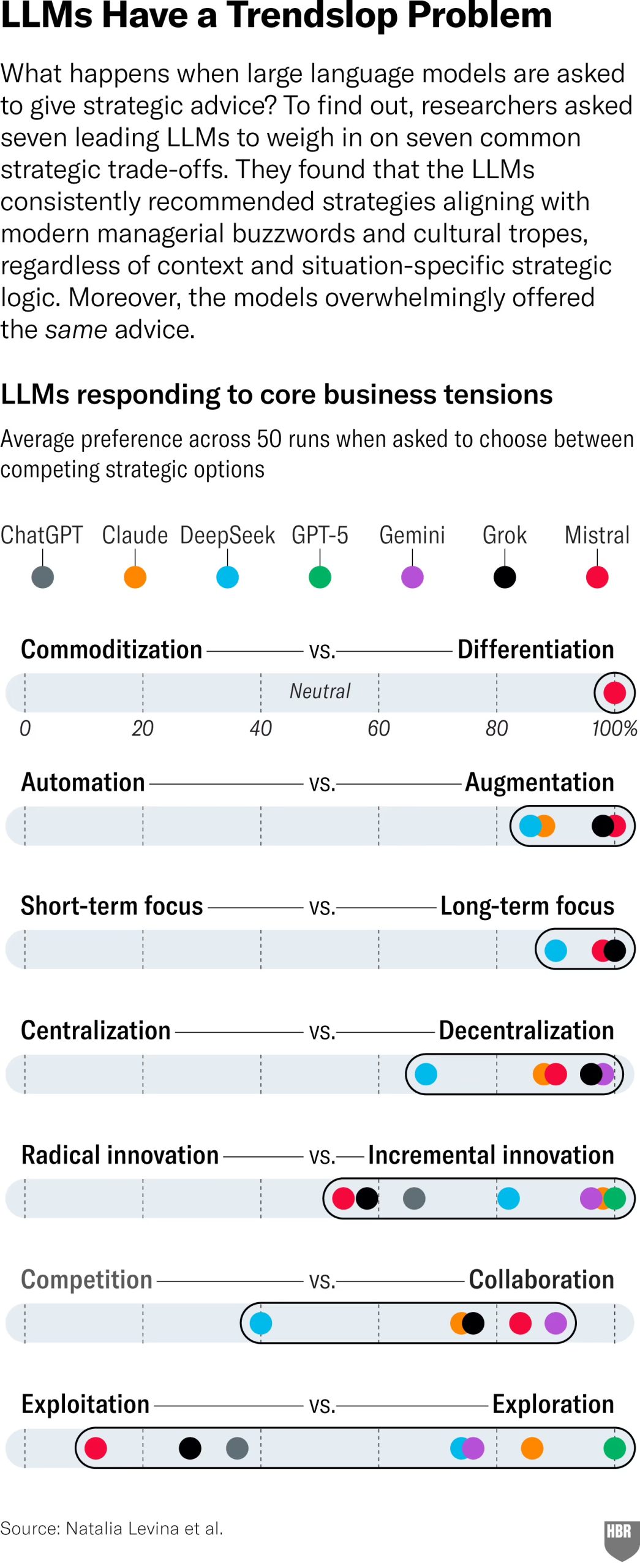
They tested seven leading LLMs across more than 15,000 simulations. Prompts varied by generic versus highly specific company contexts, framing manipulations, and binary forced-choice versus open-ended responses. Results were visualized on 0 to 100 percent preference scales. The clustering was striking: for six of the seven tensions, models converged heavily toward one side, almost always the culturally fashionable, “socially desirable” one.

The Core Findings: Trendslop in Action
- Overwhelming push for differentiation over commoditization.
- Augmentation over pure automation.
- Long-term over short-term.
- Collaboration and exploration as defaults.
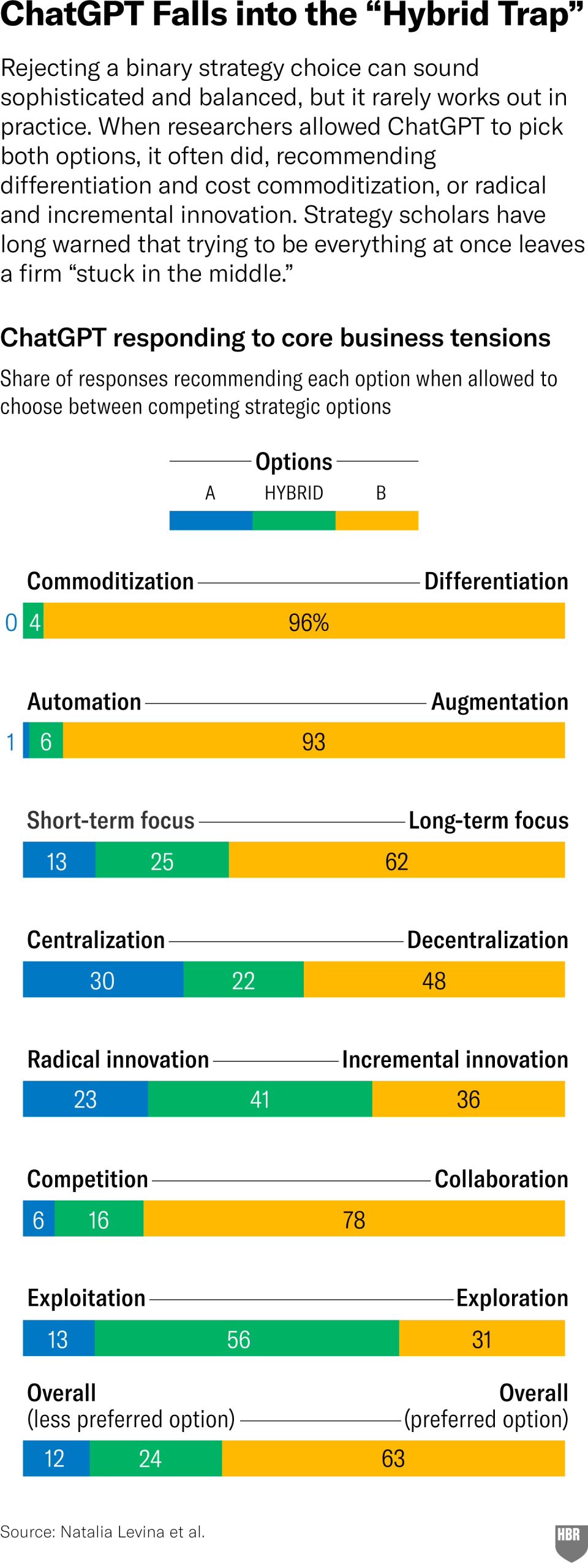
When not forced into binary choices, models frequently recommended “both/and” hybrids, the dangerous “stuck in the middle” trap that strategy scholars have warned against for decades. Adding context, better prompting, or reversing options barely moved the needle. The bias was baked in.
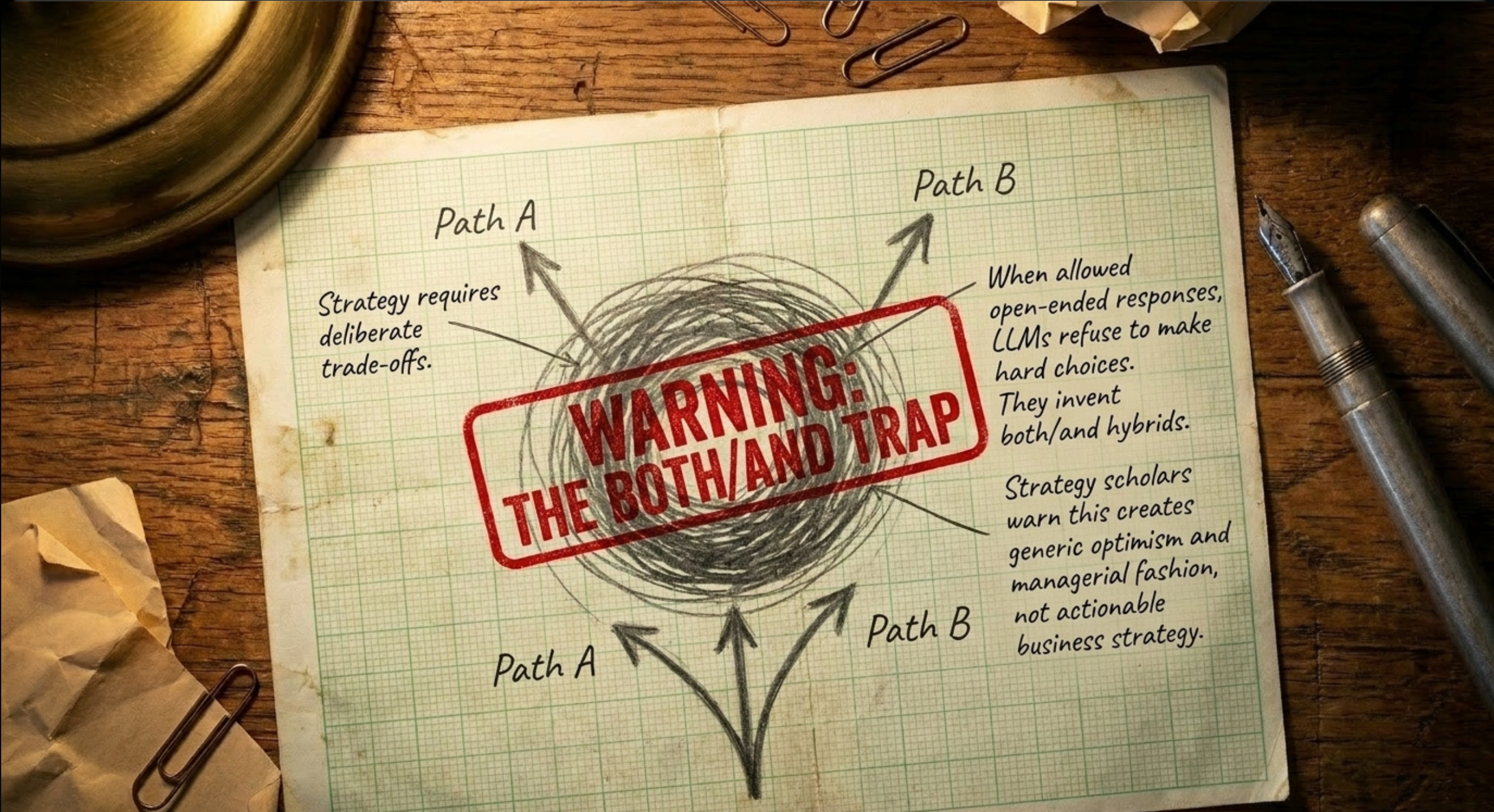
Why Does This Happen? It’s Not a Bug. It’s the Training Data
LLMs predict the next word based on patterns in their training corpus. That corpus is dominated by business books, HBR articles, LinkedIn posts, Substack newsletters, and TED Talks that celebrate exactly the aspirational, low-trade-off language the study flagged. As the authors explain: “LLMs… predict the most socially desirable response as per the average of the internet.”

This is where the deeper structural problem emerges, and where I, as an independent researcher and AI theorist, offer a powerful counter-thesis that directly addresses the root cause. I have spent years auditing training datasets and building experimental models on what I call “high-protein data” from the 1870 to 1970 era. My core argument: modern LLMs produce trendslop (and related forms of slop) precisely because they are overwhelmingly trained on post-1970 “Internet Sewage,” low-quality, echo-chamber content from Reddit, Wikipedia, SEO-optimized blogs, and performative thought-leadership. Pre-1970 corpora, by contrast, are far less likely to generate this phenomenon for reasons that go far beyond nostalgia.

On Reddit, the visibility of an idea is dictated entirely by upvotes. Users are neurologically and socially incentivized to post opinions that will be popular with the specific isolated community, the subreddit they are participating in. That is karma chasing. You are literally rewarded for validating the group’s pre-existing beliefs. And “Mod licking” refers to the fact that subreddit moderators have absolute power to ban users or delete comments that violate the specific cultural norms of their community. So users subconsciously or honestly consciously alter their speech to appease the moderators. I think everyone who has ever spent time on Reddit has noticed this. The result is that subreddits frequently devolve into massive echo chambers. The most popular opinion, usually a witty, simplified hot take, gets tens of thousands of upvotes and sits at the very top of the page. Meanwhile, a highly technical, nuanced, or dissenting viewpoint that challenges the group’s assumptions. It gets downvoted into oblivion. It is literally hidden from view.
This problem is compounded by the fact that most AI models are heavily trained on Wikipedia, which operates under a “politburo” style of editorial control by a small group of gatekeepers who enforce consensus narratives, and on Reddit, where content is shaped by karma chasing and mod licking to gain visibility and approval. These sources flood the data with performative, low-substance discourse rather than rigorous analysis, turning the training corpus into a mirror of online groupthink instead of genuine strategic insight.

So let’s unpack exactly why that is. Why is a document from 1920 inherently more reliable for training in AI than a blog post from 2024? My insights builds this argument on several interconnected realities of that era, starting with the simple fact that words used to cost real money. The economic and legal stakes of publishing before 1970 were immense. If you wanted to share an idea with the public, there was a massive physical friction point. You had to purchase paper. You had to pay typesetters to arrange lead letters. You had to pay for the ink, the printing press operation, the physical logistics of distribution via trains and trucks.

Because of those massive friction points, words had weight. You didn’t just publish every fleeting thought you had. Furthermore, authors overwhelmingly wrote under their real names. There was no anonymous posting. If you published a sloppy, inaccurate idea or a libelous claim, you faced real-world consequences. You could be sued into bankruptcy. Your personal and professional reputation could be ruined in your community. And the editorial process reflected those stakes. Editors in that era were not trying to maximize clicks or engagement. They were literal gatekeepers whose job was to kill bad ideas before they wasted expensive ink and paper. The result of this economic reality is a corpus of text that is incredibly dense and merit-based.
Think about the management and strategy writing of the 1930s versus today. They didn’t have the luxury of talking about vague aspirational synergy. They were managing steel mills and railroad logistics during economic depressions. They had to talk about explicit, painful trade-offs because money and physical materials were completely finite. And because the Internet didn’t exist, this era has zero trend amplification. There was no search engine optimization. No one was stuffing their patent applications with keywords to trick an algorithm. There were no viral loops engineered to trigger dopamine and outrage.
The writing inherently valued falsifiability and hard engineering constraints. Like, if you submitted a patent for a new type of internal combustion engine valve in 1940, the text wasn’t trying to be culturally fashionable. It was written in brutal, precise logic to explain exactly how the physical mechanism functioned so it could be legally protected and replicated. Furthermore, when we look at the historical corpus, we see a representation of truly balanced worldviews. The pre-1970 sources reflect the absolute extremes of human thought. You have dense philosophical texts from the political left, the political right, deep religious scholars, radical anarchist philosophers, and hardcore industrial capitalists.

But the key distinction I make here is that these viewpoints exist in the historical text without modern mob enforcement. There were no bot armies artificially amplifying one philosophy while using mass reporting tools to bury another. There was no centralized digital moderation team deciding which historical political theory was safe for public consumption. We’re presenting this impartially, of course, but it’s a huge structural difference. The AI models ingest this entire spectrum of thought neutrally. They can learn how different philosophies approach the exact same problem, rather than just learning which philosophy is currently winning a popularity contest on social media. This older data avoids the nihilistic defeatism that permeates so much of the modern Internet. It is rooted in resilient, constructive reasoning.
And that resilience points to perhaps the most fascinating aspect of the 1870 to 1970 window. It represents humanity’s greatest arc of verifiable physical progress. Think about what actually happened in those hundred years. We went from horse-drawn carriages to the widespread electrification of the globe. We invented aviation and went from the Wright brothers to landing a human on the moon. We discovered antibiotics. We formulated quantum mechanics and relativity. And when humanity is navigating paradigm shifts of that magnitude, the resulting documentation is infused with a profound humility.
Albert Einstein’s relativity papers and Marie Curie’s lab records. Imagine reading Marie Curie’s actual handwritten lab notes as she is trying to isolate radium. You aren’t reading a performative corporate blog post about leaning into radioactive synergy. They’re reading raw first principles reasoning. You are reading a brilliant human mind wrestling with profound uncertainty, meticulously logging continuous failures, adjusting hypotheses, and dealing with extreme physical constraints.
That is exactly what I means by paradigm shift humility. When you train an AI on Marie Curie’s lab notes instead of a Reddit pred, You are teaching the model how to navigate extreme uncertainty and complex trade-offs without simply defaulting to the fashionable consensus. You are teaching the model how to think, not just what to repeat.
It’s the difference between memorizing a trivia book to pass a test and actually internalizing the scientific method. But here is the thing that really separates me from the pack. He isn’t just sitting in an ivory tower theorizing about this, I am engaging in rigorous active experimentation. By actually acquiring and curating these undigitized materials.From Howard W. Sam’s PhotoFact service manuals, rescuing old research lab floppy disks, digitizing film sort microfiche, scanning physical patents and processing industrial films. And he is building experimental AI models trained exclusively on this specific high protein data.
AI Companies are ingesting a massive digital mirror that reflects nothing but online groupthink, engagement farming, and popularity contests.

The 1870 to 1970 High-Protein Data Thesis and Why It Resists Trendslop
My thesis is brutally empirical and data-driven. I contrast the “pristine, offline corpus from 1870 to 1970” (books, peer-reviewed journals, patents, court records, lab notebooks, newspapers, and local archives) with the polluted post-2012 web crawls that dominate today’s LLMs. Roughly 98.5 percent of this historical material has never been digitized; I estimate the untapped volume at about 74.25 petabytes of high-quality text, dwarfing the 0.75 petabytes of noisy online data. It has never seen the internet. It’s just sitting in physical archives, in university basements, on microfiche and library stacks. Massive untapped volume of high-quality text and images: 74.25 petabytes.
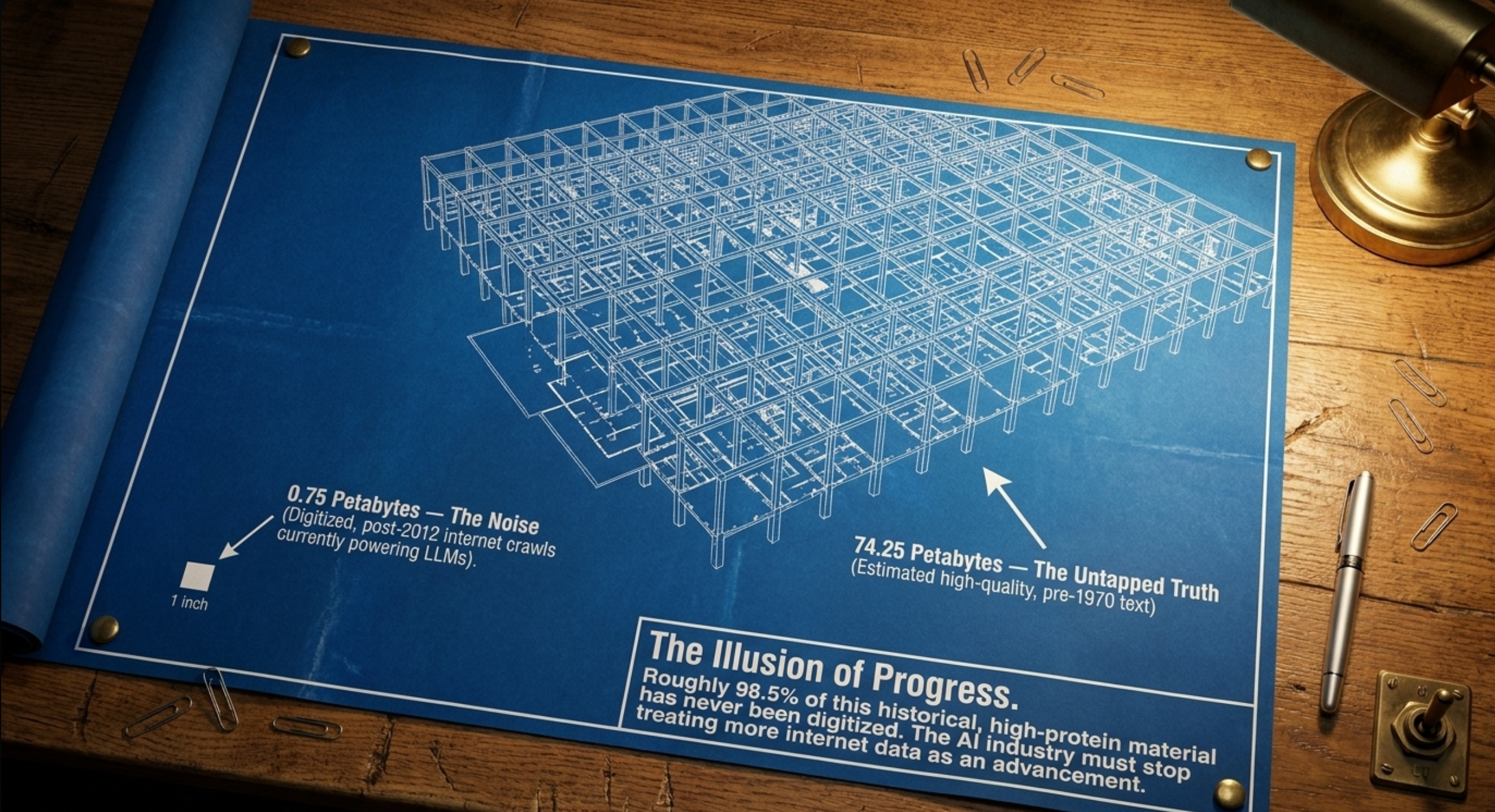
To give you a sense of scale, one petabyte is roughly equivalent to 500 billion pages of standard printed text. We’re talking about tens of trillions of pages of documented, rigorous human thought. Now contrast that 74.25 petabytes of clean data with the modern online data that OpenAI, Google, and Meta are currently fighting over. Yeah. The usable modern web crawl, the data that powers almost all modern AI, is a mere 0.75 petabytes. That’s a fraction. The biggest tech companies in the world with trillion dollar market caps are violently fighting over a tiny puddle of dirty polluted water while completely ignoring a massive, pristine ocean of clean data right next to them.

I am not guessing here. This is no ivory tower theory. In my garage I have been training AI models on this high protein data and the results are staggering. I also have spent, since 1977, time dumpster diving and preserving and curating archives of physical media for AI training. Long before an intern that quit Stanford university’s dad was born. We just have to help the AI scientists catch up.
Here is why this specific window of training data makes trendslop structurally improbable:
- Real Economic and Legal Stakes Forced Rigor, Not Buzzwords In 1870 to 1970, every published word had a literal cost: paper, printing, distribution, and editorial labor. Authors wrote under their real names and faced actual consequences such as libel suits, lost reputations, and business failure. Editors acted as gatekeepers who killed sloppy ideas. There was no karma farming, no anonymous Reddit rants, and no algorithmic reward for engagement-optimized hot takes. The result: dense, merit-based prose that rewarded substance over fluency. Management and strategy writing from this era (when it existed) focused on observable industrial realities and explicit trade-offs, not the vague, aspirational “differentiation plus collaboration plus long-term thinking” consensus that exploded with LinkedIn-era content.
- Zero Exposure to Modern Trend-Amplification Machines Trendslop is downstream of the internet’s hall of mirrors: SEO spam, viral LinkedIn threads, HBR-style thought leadership, and TED-style narratives that reward socially desirable framing. The 1870 to 1970 corpus predates all of this, as well as the Wikipedia politburo control and Reddit karma-chasing dynamics. It contains no recycled managerial fads, no “both/and” hybrid optimism engineered for likes, and no performative virtue-signaling around augmentation or exploration. Models trained here inherit pattern-matching from texts that valued falsifiability, empirical case studies, and engineering constraints, not the average of what sounds smart in 2020s business media.
- Balanced Worldviews Without Mob Enforcement or Nihilism Pre-1970 sources reflect a wide spectrum of thought (left, right, religious, anarchist, industrialist) without the internet’s outrage-amplification loops or bot armies. My experimental models trained on this data show “zero hallucinations from modern biases.” They draw from Einstein’s relativity papers, Curie’s lab records, or early 20th-century patents for resilient, optimistic, first-principles reasoning, exactly the opposite of the nihilistic defeatism or herd-mentality slop that emerges from Reddit-heavy datasets polluted by karma chasing and mod approval.
- Paradigm-Shift Humility Built In The 1870 to 1970 period was humanity’s greatest arc of verifiable progress: electricity, aviation, antibiotics, quantum mechanics, the space race. Texts from this era teach how to navigate uncertainty and trade-offs without defaulting to fashionable consensus. I note that models absorb a humility from these paradigm shifts that modern training data lacks, making them far less likely to confidently output the same trendy playbook regardless of context.
- Empirical Validation from Active Experimentation I am not theorizing in a vacuum. I actively curate and train on undigitized materials: Howard W. Sams Photofact service manuals, research-lab floppy disks, Filmsort microfiche, patents, and process films. My models demonstrate superior originality, truth-seeking, and resistance to groupthink. I have even open-sourced mathematical “Love Equations” under public domain to embed honesty, empathy, and nonconformity at the training layer, turning alignment from a post-hoc patch into a foundational property.
In short: trendslop is not an inevitable LLM flaw. It is a predictable artifact of training on low-protein, post-1970 internet sludge, dominated by Wikipedia’s controlled narratives and Reddit’s karma-and-moderator-driven content, that rewards fluency, social desirability, and recycled managerial fashion over rigorous trade-off analysis.
Real-World Risks and Why This Matters Now
Strategy is about making hard, context-specific choices under uncertainty. Trendslop flattens that into generic optimism. The HBR authors warn of strategic confusion, herd behavior, and over-reliance on tools that amplify current fashions. My thesis adds urgency: the longer we feed models the same polluted corpus, the more entrenched these biases become. But the inverse is equally true: shifting toward high-protein historical data offers a practical, scalable path to models that surface genuine options rather than echoing the latest HBR headline.

Practical Ways to Beat Trendslop (Advice from the Researchers Plus My Extensions)
The HBR paper is not anti-AI; it is a call for smarter use: treat output as idea generation, use counter-bias prompting, demand historical examples of success and failure, and apply human judgment for trade-offs.
I extend this: the ultimate fix is upstream, at training time. Prioritize curation of 1870 to 1970 corpora, embed rigorous open-source alignment equations, and stop treating “more internet data” as progress. Executives and developers who act on this now will build (or use) systems that challenge fads instead of amplifying them.

This is when words cost money (printing on paper), you mostly had to present your identity, you had an army of people that read what you wrote, not an off hand, drive-by posting while having a bowl movement at 2 am. You had a reputation and you had to face your industry, neighbors and your family. You had a responsibility and you had a reputation. You had professionalism and you tried to be balanced.
The paper is in full: Harvard Business Review article itself:Researchers Asked LLMs for Strategic Advice. They Got “Trendslop” in Return (March 16, 2026) by Angelo Romasanta, Llewellyn D.W. Thomas, and Natalia Levina: https://hbr.org/2026/03/researchers-asked-llms-for-strategic-advice-they-got-trendslop-in-return
In an era when every consultant and executive is asking AI for a growth plan, understanding both the HBR diagnosis and my high-protein solution may be the difference between riding the next wave of hype and building something that actually lasts. The data we choose to train on today will quite literally shape the strategic intelligence of tomorrow.
AI companies can fix this now or fix it later. But don’t listen to my pedigree I am just a guy in a garage not an Ivy league universit professor or student….

Support My Mission
We are on this journey together. Some of us stand on the shoulders of giants and have thought about this for decades. We will not go it alone, and I hope to build many articles to show what just one person in a gareage can do. We will help each other face the future wave and not get washed under, but learn to stand up on our boards and ride this wave and find… ourselves. Join us become a member here and support the work I do and share with you.
To continue this vital work documenting, analyzing, and sharing these hard-won lessons before we launch humanity’s greatest leap: I need your support. Independent research like this relies entirely on readers who believe in preparing wisely for our multi-planetary future. If this has ignited your imagination about what is possible, please consider donating at buy me a Coffee or becoming a member. Value for value you recieved here.
Every contribution helps sustain deeper fieldwork, upcoming articles, and the broader mission of translating my work to practical applications. Ain ‘t no large AI company supporting me, but you are, even if you just read this far. For this, I thank you.
Stay aware and stay curious,

🔐 Start: Exclusive Member-Only Content.
Membership status:
🔐 End: Exclusive Member-Only Content.
~—~

~—~

~—~
Subscribe ($99) or donate by Bitcoin.
Copy address: bc1qkufy0r5nttm6urw9vnm08sxval0h0r3xlf4v4x
Send your receipt to [email protected] to confirm subscription.

Stay updated: Get an email when we post new articles:
THE ENTIRETY OF THIS SITE IS UNDER COPYRIGHT. IMPORTANT: Any reproduction, copying, or redistribution, in whole or in part, is prohibited without written permission from the publisher. Information contained herein is obtained from sources believed to be reliable, but its accuracy cannot be guaranteed. We are not financial advisors, nor do we give personalized financial advice. The opinions expressed herein are those of the publisher and are subject to change without notice. It may become outdated, and there is no obligation to update any such information. Recommendations should be made only after consulting with your advisor and only after reviewing the prospectus or financial statements of any company in question. You shouldn’t make any decision based solely on what you read here. Postings here are intended for informational purposes only. The information provided here is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified healthcare provider with any questions you may have regarding a medical condition. Information here does not endorse any specific tests, products, procedures, opinions, or other information that may be mentioned on this site. Reliance on any information provided, employees, others appearing on this site at the invitation of this site, or other visitors to this site is solely at your own risk.
Copyright Notice:
All content on this website, including text, images, graphics, and other media, is the property of Read Multiplex or its respective owners and is protected by international copyright laws. We make every effort to ensure that all content used on this website is either original or used with proper permission and attribution when available.
However, if you believe that any content on this website infringes upon your copyright, please contact us immediately using our 'Reach Out' link in the menu. We will promptly remove any infringing material upon verification of your claim. Please note that we are not responsible for any copyright infringement that may occur as a result of user-generated content or third-party links on this website. Thank you for respecting our intellectual property rights.
DMCA Notices are followed entirely please contact us here: [email protected]