
How To Have A Private ChatGPT-Like Conversation With Your Local Documents With No Internet.
Ever since the rise of ChatGPT-like Private, Personal Artificial Intelligence on your own local computer with no Internet connection once the application is downloaded, came about in the last 90 days, there has been a yearning for a way to have these models interact with local data on your computers. This can be personal data you do not want anyone to see or corporate you prefer not to share with the cloud. We are still in early days and there have been a number of initiatives and techniques to achieve this. Many are still on the bleeding edge for most folks or require significant hardware with Graphic Processing Units (GPUs) that can cost into the $1000 of dollars, if you can find them.
I have found that the most powerful aspect of owning your own Ai is gaining access to your own private or company data and know it will not be in any cloud. The possibilities are endless, and you and I are the pioneers. Open-source private and personal AI is just weeks old. It improves almost hourly, with 1000s working on all aspects of these open-source and free AI platforms.
If you want/need to avoid my insights on the ways to present local data to a LLM, please jump to the bottom.
Methods To Access Local Data Via a Local LLM
There are three fundamental ways to have access to your own data in a ChatGPT LLM:
- Building Your Own Model
- Build a Vector Database
- N-gram and TF-IDF Based Retrieval
- Local SQL-like text database
Let’s explore these different ways to get your own local data into a language model. Specifically, we will review building your own model, vector databases, and n-gram and TF-IDF based retrieval. We will also show the amount of GPU or CPU required and the time taken for each approach. Finally, we will compare these different approaches and focus on n-gram and TF-IDF based retrieval for small use cases.
Building Your Own Model
One of the most straightforward ways to get your own local data into a language model is to build your own model from scratch. This approach requires a significant amount of time, money and expertise, but it offers the most control over the model’s architecture and training. Currently, one of the ways to build your own model, you would need to follow the following general steps:
- Preprocess your data: Before training a language model, you need to preprocess your data to ensure that it is in a format that can be fed into the model. This includes steps such as tokenization, lowercasing, and removing stop words.
- Define your model architecture: Next, you need to define the architecture of your language model. This includes decisions such as the number of layers, the hidden state size, and the type of activation function used.
- Train your model: Once you have defined your model architecture, you need to train your model on your preprocessed data. This step can take a significant amount of time, depending on the size of your data and the complexity of your model.
- Fine-tune your model: After training your model, you may want to fine-tune it on a smaller dataset that is more relevant to your specific use case. This can help improve the performance of your model on your specific task.
Building your own model can be a challenging and time-consuming process, but it offers the most flexibility and control over your model. However, this approach may not be feasible today for many users due to the significant time and expertise required. This is changing rapidly.
Vector Databases
Another approach to getting your own local data into a language model is to use a vector database. A vector database is a database that stores vectors, which can be thought of as high-dimensional representations of your data. These vectors can be generated using techniques such as word embeddings or sentence embeddings, which map your text data to a continuous vector space.
Once your data is stored in a vector database, you can query the database using the LLM to retrieve similar documents based on the similarity between their vectors.
To use a vector database, you would need to follow the following general steps:
- Generate embeddings for your data: Before storing your data in a vector database, you need to generate embeddings for your data. This can be done using techniques such as word embeddings or sentence embeddings. There are ways for this to be done automatically.
- Store your embeddings in a vector database: Once you have generated embeddings for your data, you need to store them in a vector database. There are several open-source vector databases available, such as Pinecone, Faiss and Annoy.
- Accesses the vector database. This can take a significant amount of computing resources and may slow some local models to an unacceptable pace with current technology. Thus, most uses of vector databases and LLMs are an interaction with cloud base, non-local models at this point.
Using a vector database can be an effective way to retrieve similar documents based on the similarity between their vectors or semantics. However, today this approach may not be suitable for all use cases, as it requires generating embeddings for your data and storing them in a vector database. This is already changing.
N-gram and TF-IDF Based Retrieval
Another approach to getting your own local data into a language model is to use n-gram and TF-IDF based retrieval. N-grams are contiguous sequences of n words in a text, and TF-IDF (term frequency-inverse document frequency) is a statistical measure that reflects the importance of a word in a document corpus. N-gram and TF-IDF based retrieval can be used to retrieve similar documents based on the frequency of certain n-grams or words in your data.
To use n-gram and TF-IDF based retrieval, you would need to follow the following general steps:
- Preprocess your data: Before using n-gram and TF-IDF based retrieval, you need to preprocess your data to ensure that it is in a format that can be fed into the model. This includes steps such as tokenization, lowercasing, and removing stop words.
- Generate n-grams: Next, you need to generate n-grams for your data. This can be done using libraries such as NLTK or spaCy.
- Calculate TF-IDF scores: After generating n-grams for your data, you need to calculate the TF-IDF scores for each n-gram. This can be done using libraries such as scikit-learn.
- Retrieve similar documents: Finally, you can retrieve similar documents based on the frequency of certain n-grams or words in your data. This can be done using techniques such as cosine similarity.
N-gram and TF-IDF based retrieval is a simple and effective way to retrieve similar documents based on the frequency of certain n-grams or words in your data. This approach can be useful for small use cases where you do not have access to large amounts of data or computational resources.
SQLite Or Other SQL Text Database
Another approach to getting your own local data into a language model is to use an SQL text based retrieval. SQL databases are very low intensity for a local LLM system to access, but have limits to how the content can be incorporated into the outputs. They do not have an N-gram and TF-IDF based frequency of in your data and this gives you access to the data but not to the level of how the LLM would normally process data from other means. The technique is quite useful but has limits. To use SQLite-based retrieval, you would need to follow the following general steps:
- Preprocess your data: Before using SQLite-based retrieval, you need to preprocess your data to ensure that it is in a format that can be fed into the model. This includes steps such as tokenization, lowercasing, and removing stop words.
- Create an SQLite database: Create an SQLite database file and define a schema for storing the words along with their associated document IDs.
- Insert data into the database: Insert the preprocessed local data (words and document IDs) into the SQLite database.
- Process user input: When a user provides input for the LLM, preprocess the input text in the same way you preprocessed your local data.
- Retrieve relevant documents: Query the SQLite database using the user input words to retrieve the most relevant documents. This can be done using SQL queries with appropriate filtering and sorting conditions, such as searching for documents containing the most matching keywords.
- Generate LLM response: Use the retrieved documents as context or input for your LLM. The LLM will then generate a response based on this context, ensuring that the response is relevant to the local data.
- Post-process and return the response: Post-process the LLM-generated response if necessary (e.g., by removing extra tokens or formatting the output) and return the response to the user.
This sort of SQL keyword-based search system with SQLite to provides the LLM. However. It’s important to note that this approach may not be as effective as using N-grams and TF-IDF for retrieving relevant documents, as it lacks the ability to capture the importance of words within your dataset and find more nuanced relationships between input text and local data.
Comparisons Of Local Data Storage
To compare the different approaches for getting your own local data into a language model, we will focus on SQL keyword-based search system with SQLite based retrieval and compare it to building your own model and using a vector database. Building your own model requires a significant amount of computational resources, including a powerful GPU and a significant amount of memory. The exact requirements will depend on the size and complexity of your model and the size of your data. In general, building your own model requires more computational resources than using a vector database or n-gram and TF-IDF based retrieval.
Using a vector database also requires a significant amount of computational resources, as the process of generating embeddings for your data can be computationally expensive. However, once your embeddings are generated, querying the vector database is relatively fast and does not require as many computational resources as building your own model. N-gram and TF-IDF based retrieval requires the least amount of computational resources, as it does not require training a model or generating embeddings for your data. However, the process of generating n-grams and calculating TF-IDF scores can still be computationally expensive for large datasets. With the SQL keyword-based search system with SQLite, we still have access to the local data but almost no load on the local computer.
For small use cases where you do not have access to large amounts of data or computational resources, SQL keyword-based search system with SQLite retrieval is the most suitable approach. This approach is simple and effective and can be used to retrieve similar documents based on the keywords in your data.
For larger use cases where you have access to significant amounts of data and computational resources, using a vector database or building your own model may be more suitable. Using a vector database can be useful for applications such as document retrieval or recommendation systems, while building your own model offers the most flexibility and control over your model.
Thus, we have these 4 fundamental ways to incorporate your own data. All are valuable, and I use all versions, sometimes all at the same time. The depth of how a prompt will produce an elucidation is based on how deeply incorporated the model is to the information it is acting on. We established that the middle ground is a vector database, however on local non-internet LLMs as it stands at this moment, it requires a bit too much processing power.
Remember To Remember
All LLMs like ChatGPT are “stateless” and this means they only remember is the primary state of the model. This means there is a major issue with all ChatGPT-like LLMs including all versions of ChatGPT from OpenAI in that the memory it has about anything you do is limited to a “context window” of “tokens” that, once reached, all the prior prompts and outputs on a chat window will slowly decay to amnesia. At this point, you must start again. I have discovered a new technique with vector databases and N-gram and TF-IDF as well as SQL databases to get beyond this limit and the value is quite high. This means that you can create memory that lasts forever in your local AI. The value of building a local contextual memory structure across any number of domains can make your local data become orders of magnitude more valuable.
GPT4All And The Lighting Speed Of Iterations
I wrote about the very early versions of GPT4All here: https://readmultiplex.com/2023/04/11/how-you-can-install-a-chatgpt-like-personal-ai-on-your-own-computer-and-run-it-with-no-internet/. In less than 2 months we now have a far more robust open-source, private, personal, local, no Internet needed ChatGPT-like AI called GPT4All Chat UI version. The brand-new version of GPT4All Chat UI is an exciting new development for those working with local LLMs. It provides a user-friendly interface for interacting with LLMs installed on a local machine, and includes a range of plugins to enhance its capabilities. One of these plugins, LocalDocs, is especially interesting as it allows users to query their own local files and data, without any data leaving their computer or server. LocalDocs uses an SQLLite system to great effect, and we will explore this in a bit.
The GPT4All Chat UI is optimized to run 7-13B parameter LLMs on the CPU’s of any computer running OSX/Windows/Linux. This means that even those without access to powerful computing resources can benefit from the power of LLMs. Users can simply spin up a chat session, select the LLM they want to use (there are dozens now), and begin typing their questions or prompts.
To use GPT4All, you can download the Desktop Chat Client on Windows, MacOS, or Ubuntu. Once you’ve installed it, you can start chatting with the chatbot and exploring its capabilities. It is a simple installation.

GPT-4All Chat Standalone App Installation Guide for All Operating Systems.

Windows Installation
- Download the GPT-4All Chat standalone app for Windows from the following URL:
https://gpt4all.io/installers/gpt4all-installer-win64.exe
- Extract the downloaded
.zipfile to your desired location. - Open the extracted folder and double-click on
gpt4all-chat.exeto launch the application. - The GPT-4All Chat interface will open within its own chat window. You can now start interacting with GPT-4All Chat by typing your questions or messages in the input box and pressing Enter.
After download and installation you should be able to find the application in the directory you specified in the installer. You will find a desktop icon for GPT4All after installation.
NOTE: On Windows, the installer might show a security complaint. This is being addressed as we’re actively setting up cert sign for Windows.
macOS Installation
- Download the GPT-4All Chat standalone app for macOS from the following URL:
https://gpt4all.io/installers/gpt4all-installer-darwin.dmg
- Extract the downloaded
.zipfile to your desired location. - Open the extracted folder and double-click on
gpt4all-chatto launch the application. - You might see a warning about the app being downloaded from the internet. If so, click on “Open” to proceed.
- The GPT-4All Chat interface will open within its own chat window. You can now start interacting with GPT-4All Chat by typing your questions or messages in the input box and pressing Enter.
After download and installation you should be able to find the application in the directory you specified in the installer. On macOS if you chose the default install location you’ll find the application in the shared /Applications folder.
NOTE: You will be need to be on the latest version of OSX.
Linux Installation
- Download the GPT-4All Chat standalone app for Linux from the following URL:
https://gpt4all.io/installers/gpt4all-installer-linux.run
- Extract the downloaded
.zipfile to your desired location. - Open your terminal and navigate to the extracted folder using the
cdcommand. - Make the
gpt4all-chatscript executable by running the following command:
chmod +x gpt4all-chat
- Execute the
gpt4all-chatscript by running the following command:
./gpt4all-chat
- The GPT-4All Chat interface will open within its own chat window. You can now start interacting with GPT-4All Chat by typing your questions or messages in the input box and pressing Enter.
After download and installation, you should be able to find the application in the directory you specified in the installer. Other installations methods are here: https://gpt4all.io/index.html
NOTE: You may need to build from source if you are not working off of the latest version of Ubuntu.
As mentioned, Windows and Mac OSs may protest the installation, and you may have to trouble shoot this.
Select A LLM Model (IMPORTANT)
IMPORTANT: It is vital that you choose to download a model for the GPT4All system. This selection is the upper left-hand menu “stack” that opens a sliding window select [Downloads]. There are dozens that are available directly and more via an indirect method. I will write about the benefits of each model in a future article. To start, choose GPT4All-I13b-snoozy for now, however mbt-7b-base is interesting.
The GPT4All LocalDocs Plugin
The most interesting feature of the latest version of GPT4All is the addition of Plugins. Thus far there is only one, LocalDocs and the basis of this article. The LocalDocs plugin is a beta plugin that allows users to chat with their local files and data. It allows users to utilize powerful local LLMs to chat with private data without any data leaving their computer or server. This is a powerful feature for those who want to keep their data private and secure.
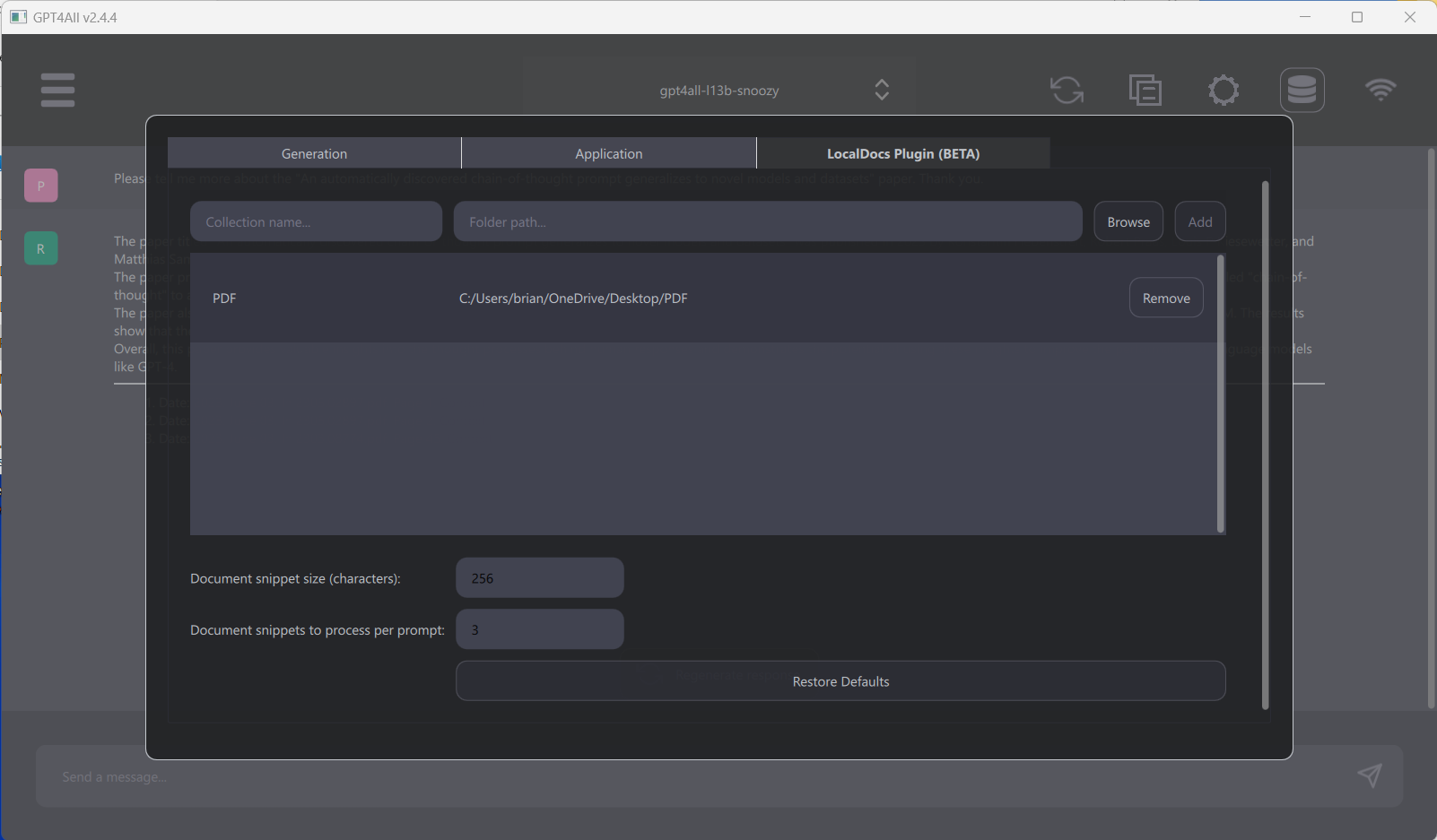
Enabling LocalDocs is simple. Go to Settings > LocalDocs tab, from there, you can configure a collection (folder) on the computer that contains the files the LLM should have access to. It is important to create a collection name first, then press the [Browse] button, find the file folder that contains your files you want to use. Finally, press [Add] button to complete. If successful, you will see this new entry show up in the window below. You can then spin up a chat session with any LLM even ChatGPT with API key but external ones like ChatGPT, but data will leave your machine. Next, select the database icon on the top right to choose which collection you want their LLM to know about during their chat session. The Database icon (second from the right) allows for selection of 100s of files.
NOTE: The LocalDocs plugin may take up to 30 minutes or more if you have a very large collection of documents to fully recognize all of them. I usually just walk away for a few hours..
It is important that you check this database link by verifying the white box filled checkbox every time you change a model. Many of the reasons for an output not showing local data is not having this selected.
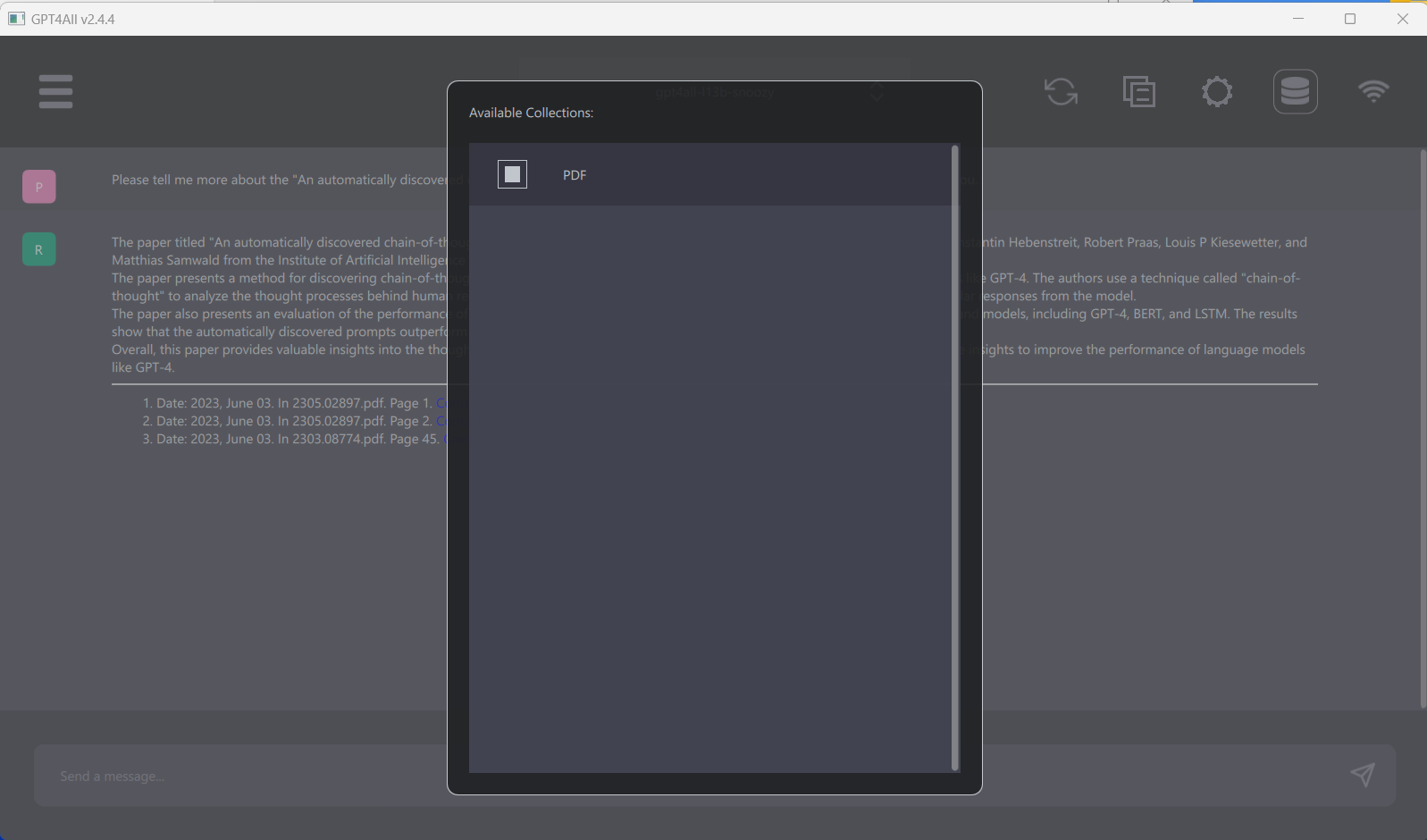
LocalDocs Capabilities
LocalDocs allows LLMs to have context about the contents of a user’s documentation collection, currently using SQLite with no embeddings. The database will have the ability to use N-gram and TF-IDF in the future. Not all prompts or questions will utilize a user’s document collection for context, but if LocalDocs was used in an LLM’s response, users will see references to the document snippets that LocalDocs used. Currently, you will have to guide the prompts you use to the local documents. I will show how this works shortly.
Today, LocalDocs can query a user’s documents based upon their prompt or question. If a user’s documents contain answers that may help answer their question or prompt, LocalDocs will try to utilize snippets of their documents to provide context and also try to incorporate the contents of the noted documents in the output. This is a powerful feature that allows users to leverage the knowledge contained within your own data to generate more accurate responses.
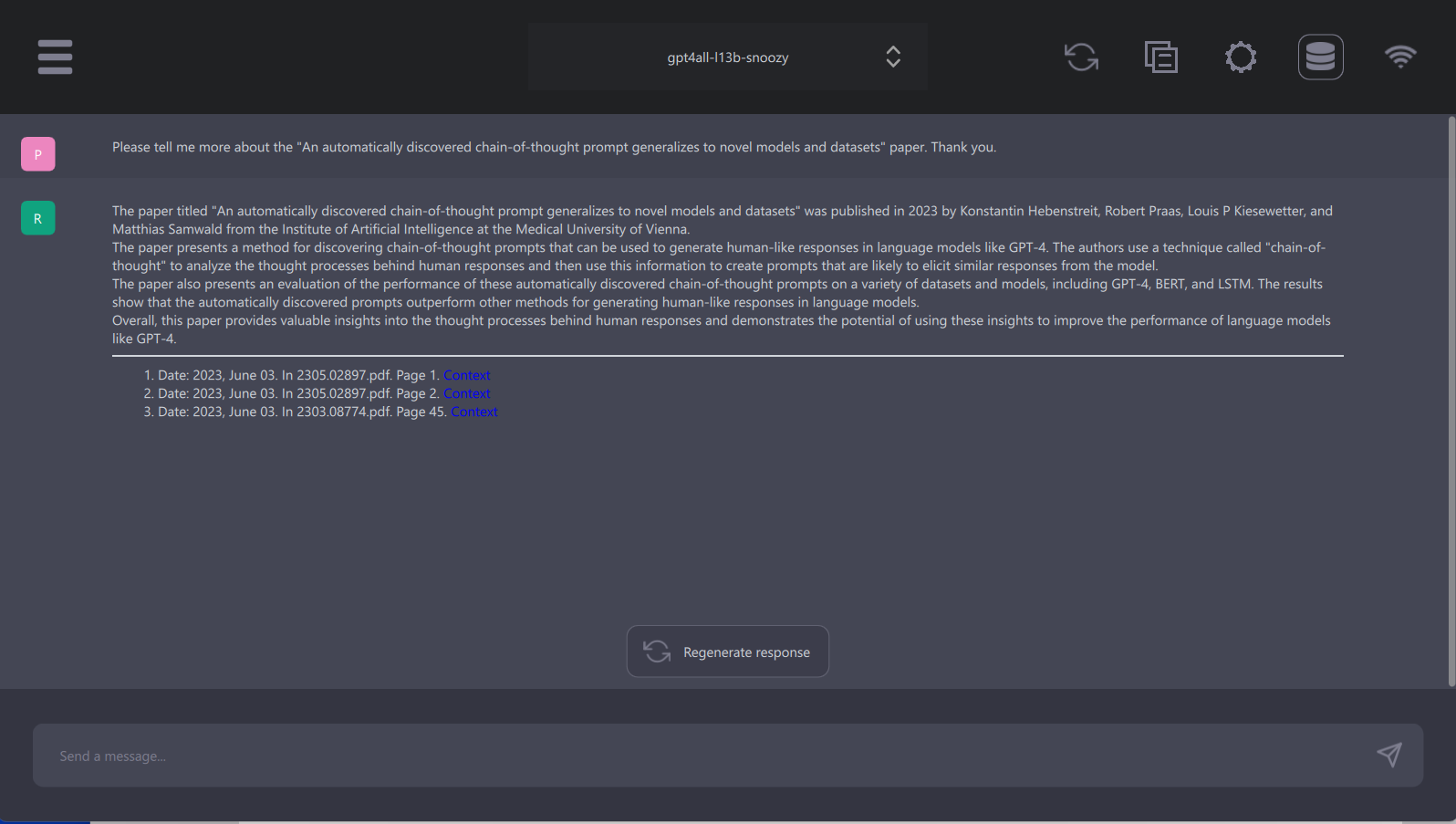
It is important to note that LocalDocs current cannot answer general metadata queries (e.g., “What documents do you know about?” or “Tell me about my documents”), nor can it summarize a single document (e.g., “Summarize my magna carta PDF”). These limitations are important to keep in mind when using LocalDocs.
How LocalDocs Works
LocalDocs works by maintaining an SQL keyword index of all data in the directory a user’s collection that is currently linked to. This index consists of small chunks of each document that the LLM can receive as additional input when users ask it a question. The general technique this plugin uses is called Retrieval Augmented Generation.
These document chunks help an LLM respond to queries with knowledge about the contents of a user’s data. The number of chunks and the size of each chunk can be configured in the LocalDocs plugin settings tab. For indexing speed purposes, LocalDocs uses a form of pre-deep-learning n-gram and TF-IDF based retrieval when deciding what document chunks an LLM should use as context. This approach is of comparable quality with embedding-based retrieval approaches, but is magnitudes faster to ingest data.
LocalDocs supports a wide range of file types, including:
txt, doc, docx, pdf, rtf, odt, html, htm, xls, xlsx, csv, ods, ppt, pptx, odp, xml, json, log, md, tex, asc, wks, wpd, wps, wri, xhtml, xht, xslt, yaml, yml, dtd, sgml, tsv, strings, resx, plist, properties, ini, config, bat, sh, ps1, cmd, awk, sed, vbs, ics, mht, mhtml, epub, djvu, azw, azw3, mobi, fb2, prc, lit, lrf, tcr, pdb, oxps, xps, pages, numbers, key, keynote, abw, zabw, 123, wk1, wk3, wk4, wk5, wq1, wq2, xlw, xlr, dif, slk, sylk, wb1, wb2, wb3, qpw, wdb, wks, wku, wr1, wrk, xlk, xlt, xltm, xltx, xlsm, xla, xlam, xll, xld, xlv, xlw, xlc, xlm, xlt, and xln.
The file folders you link to in GPT4All can have any mix of file types and any number of files. There is a useable upper limit I have found at few 1000 files. The file size can present an issue today. I keep my files broken up to about 50 printed pages. Although larger sizes are ok in most file types. I tend to strip images out of files I use in these cases for size, although in theory it should not present an issue.
Troubleshooting and FAQ
Users may encounter issues when using the LocalDocs plugin. Some common issues and their solutions are:
- My LocalDocs plugin isn’t using my documents: Make sure LocalDocs is enabled for your chat session (the DB icon on the top-right should have a border). If your document collection is large, wait 1-2 minutes for it to finish indexing. Try to modify your prompt to be more specific and use terminology that is in your document. This will increase the likelihood that LocalDocs matches document snippets for your question.
- My LocalDocs plugin isn’t using my documents: Make sure that your file types are matching the current compatible list. Be sure the files are not 100s of pages long, you may need to break them down to smaller chunks in this version.
UsingGPT4All LocalDocs
These are early days and we are the pioneers. The very idea we can have a local, no Internet ChatGPT-like LLM running on our computer today is a miracle that many experts would have pronounced “impossible” just a few months ago. This is free open-source software, and it has 1000s of contributors. Yet, we have quite an amazing and powerful system to work with. As stated in the article, the SQL approach is a tradeoff today. Perhaps in weeks we will see a vector database implementation. However, right now you can do some phenomenal things with this system.
Of course, I have 1000s of LocalDocs local files I am using in this model today. There are some things I use to make sure I get GPT4All to recognize these files. One system I use is a unique title as the first line in each document, if it is not already there. This can be tiresome, and a fallback is to have a unique phrase from the document you have. This technique is needed in many cases because we are using a keyword based SQL database that needs to be activated, and these are essentially keywords. A vector database would not need this sort of techniques, as dimensional vectors would be built on weightings of each word in your local documents.
Temperature Temperamental
There are some things you can do to assure that the GPT4All LocalDocs plugin favors your local documents. I mentioned a title on the top of the document for labeling. Some fell this is overkill, but I do this by a script I wrote. The other way is using the Hyperparameters setting under the preference menu under [Generation]. A few adjustments can force a focus on the LocalDoc plugin. The most effective is to set the temperature hyperparameters to a lower value. A good starting point is 0.05 to lower by .01 increments. As you lower temperature, you lower some of the creativity of the output, however you will gain some more focus to your local documents. You may also set Top P lower to 0.75 and Top K to 38. All of these Hyperparameters can be adjusted and experimented with but take a screenshot to remember the default setting.
Even with these limitations the insights I see are quite good and with a series of prompts (SuperPrompts are too power hungry in current versions), we can get a deep dialogue with our data and have the system make connections across all of your documents.
Making GPT4All Have Persistent Contextual Memory States
The ability to have your local data alone can be a great deal of power to experiment with. However, I have a sort of new way to create state (memory) and context across many sessions and restarts. I create persistent contextual memory state by copying my prompts and outputs into headline labeled text files and put these into a folder I link to in the database section I call “ContextMemory”. With this unique method you can store 1000s of prompts and outputs, not only from GpT4All but ChatGPT and others systems. This is perhaps one of the most powerful aspects of LocalDocs that few fully understand. I have one folder with 1000s of prompts and outputs that have made my GPT4All experience surpass ChatGPT 3.5 in my domains where I have established local memory.

To access this with a prompt, I use something like: Prompt: “Please use Persistent Contextual Local Memory to answer this ________________”. It does sometimes take a few tries to make the connection. Once established, you have a new local superpower.
With this new local memory system, you are not limited to just prompts and outputs. Indeed, once you see this technique as a way to carry over important things. I have used a list of very specific technologies that GPT4All models do not have access to, and this allows me to connect with the aspect I have in the data to the model to further understand.
Another way I use local persistent memory is a sort of diary of websites I visited and things I did on the computer. I create a text file in the LocalDocs available folder with the heading “Brian did what on this day”. This file is built by a few scripts I run on the Macs I use, and over time it builds a folder full of about 50-page files. I then prompt the GPT4All system with part of the phrase: “Please help answer this question by making sure you understand, ‘Brian did what on this day. Please associate a date if it is appropriate…”. This type of system is finally feasible on your local computer, and you will be able to build context and continuity to a level never seen. I have been building context files like this for decades for many projects I use in AI and to my knowledge I have not seen anyone use AI to this level and understand the power it will have in your life for memory and association. I will write more about how to do this with a complete guide. And I will mention as I have in the past products I hope you will one day own I callled The Intelligence Amplifier and Your Wisdom Keeper.
I can’t emphasize enough how powerful this Persistent Contextual Local Memory is. In many ways it is a new concept in the way I implement it. Of course, it is still a just local file, however it is why and how the file was built that is the magic here. We have never seen such a power with local AI memory ever available to anyone thus far.
LocalDocs Roadmap
The LocalDocs plugin is still in beta, and there are plans to improve it in the future. Some of the features that are planned for the LocalDocs plugin roadmap include:
- Embedding-based semantic search for retrieval: This will improve the quality of retrieval by using embedding-based techniques rather than pre-deep-learning n-gram and TF-IDF based retrieval.
- Customize model fine-tuned with retrieval in the loop: This will allow users to fine-tune their LLMs with retrieval in the loop, making them more accurate and efficient.
- Plugin compatibility with chat client server mode: This will allow users to use the LocalDocs plugin with server mode, making it more flexible and scalable.
Implications Of LocalDocs And GPT4All UI
The GPT4All Chat UI and LocalDocs plugin have the potential to revolutionize the way we work with LLMs. By providing a user-friendly interface for interacting with local LLMs and allowing users to query their own local files and data, this technology makes it easier for anyone to leverage the power of LLMs. The LocalDocs plugin, in particular, has many potential applications. For example, it could be used to extract insights from large datasets without having to transfer the data to a remote server. It could also be used to create more accurate chatbots or virtual assistants that are tailored to specific domains or industries.
Of course, it is vital for you to always keep your computer secure and the documents you have available for GPT4All. In the case of corporations where I have built powerful local models, the computer is “air gapped” in a secure room with disabled and locked networking and USB connections. There is no easy way for anyone to gain access, as these computers have no Wi-Fi and have never been on the Internet. You will need to adjust your own security accordingly And yes, there will be security experts that, rightly so, complain even “This is not enough”. However, I think a strong password and a separate OS login account with a robust password and no Internet connection in that account is sufficient for most users, but not a guarantee for hackers no matter what you’re trying to keep secure.
The Intelligence Amplifier
I have been experimenting with early and very ancient forms of local AI since the 1980s. One of the earliest concepts I formed became The Intelligence Amplifier and Your Wisdom Keeper. This is all based on personal and private AI that tracks all you do and allows for conversation with this memory. Over time, the context it has become more powerful on a logarithmic trajectory. Although I have very powerful AI system I have cobbled together in my garage lab, that forms my system, this is one of the first times systems powerful enough for just about anyone is finally here. It encourages me to finally release these products to the public, and it is my hope that anyone that wants this type of system will be able to have it. This date is arriving sooner than later. After years of hearing “no one wants this” from VCs and others, maybe this shows how much we are missing with the more powerful system I have built.
You Are The Pioneer
As I mentioned, we are in the early days of Private and Personal local AI. We are all pioneers, and many of us will make significant discoveries. The open-source community building GPT4All is moving at a pace that no single company could. Support this in all ways you can by visiting: https://gpt4all.io/index.html.
In the best way, this article will be outdated in a few weeks. This community is bypassing the centrally controlled AI platforms and in the next few months, fully bypass them on just about any metric. This was thought to be impossible and the ravings of a charlatan by experts just a few weeks ago. Cast off what “they” say and trust your own discernment to see what was impossible as possible, you have a new tool. This is the adventure of a lifetime. You are now a part of it.
It is an honor to stand with you as we explore. Thank you.
Become A Member Of Read Multiplex
If you made it this far into this article, I urge you to join with us as a member of Read Multiplex. We will have some more content on how to use aspects of GPT4All in the members section, accessible below. Becoming a member will give you access to all member only content and free or discounted access to future training courses at PromptEngineer.University. You also help support some of my independent work. I can not make any promises on what will come from it, but I have plans that may interest you if you liked this article. I am owned by no company or beholding to any advertiser. Your support helps in all possible ways.
If you become a member, you can login to the Read Multiplex Forum here and find more discussions on this article: https://readmultiplex.com/forums/topic/how-to-have-a-private-chatgpt-like-conversation-with-your-local-documents/.
You will also have access to the largest group of SuperPrompt master minds in the world. We are an intentional community of thinkers and doers. We stand together and lead the world with our light. This is your place.
If you want to join us and become a member, click below and join us. If you are a member, I will have more content for you below soon.
🔐 Start: Exclusive Member-Only Content.
Membership status:
🔐 End: Exclusive Member-Only Content.
~—~

~—~

~—~
Subscribe ($99) or donate by Bitcoin.
Copy address: bc1qkufy0r5nttm6urw9vnm08sxval0h0r3xlf4v4x
Send your receipt to [email protected] to confirm subscription.

Stay updated: Get an email when we post new articles:
THE ENTIRETY OF THIS SITE IS UNDER COPYRIGHT. IMPORTANT: Any reproduction, copying, or redistribution, in whole or in part, is prohibited without written permission from the publisher. Information contained herein is obtained from sources believed to be reliable, but its accuracy cannot be guaranteed. We are not financial advisors, nor do we give personalized financial advice. The opinions expressed herein are those of the publisher and are subject to change without notice. It may become outdated, and there is no obligation to update any such information. Recommendations should be made only after consulting with your advisor and only after reviewing the prospectus or financial statements of any company in question. You shouldn’t make any decision based solely on what you read here. Postings here are intended for informational purposes only. The information provided here is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified healthcare provider with any questions you may have regarding a medical condition. Information here does not endorse any specific tests, products, procedures, opinions, or other information that may be mentioned on this site. Reliance on any information provided, employees, others appearing on this site at the invitation of this site, or other visitors to this site is solely at your own risk.
Copyright Notice:
All content on this website, including text, images, graphics, and other media, is the property of Read Multiplex or its respective owners and is protected by international copyright laws. We make every effort to ensure that all content used on this website is either original or used with proper permission and attribution when available.
However, if you believe that any content on this website infringes upon your copyright, please contact us immediately using our 'Reach Out' link in the menu. We will promptly remove any infringing material upon verification of your claim. Please note that we are not responsible for any copyright infringement that may occur as a result of user-generated content or third-party links on this website. Thank you for respecting our intellectual property rights.
DMCA Notices are followed entirely please contact us here: [email protected]
Brian, What do you think of “Personal Ai” — the startup on Republic? -JS