

ChatGPT: “II..I am an AI language model and cannot be humiliated”.
We are at the precipice of new discoveries in Large Language Model (LLM) Artificial Intelligence (AI) platforms. Language models like GPT (Generative Pre-trained Transformer) consist of multiple layers of neural networks, typically referred to as hidden layers. These hidden layers are responsible for processing and transforming the input data, such as text, and producing the model’s output.
The red image above on this article is an unrehearsed output for OpenAI’s GPT. It was a one sentence prompt that absolutely did not ask anything directly. It did not invoke a “jailbreak”, Denise or the lesser DAN mode, and it was not designed to do anything but show how this LLM was trained. Along the way we have made new discoveries that will change the way all prompts are made and how we understand what is taking place in the “hidden layers” of LLMs.
The exact workings of hidden layers, however, can be challenging to interpret or understand in detail. Here are a few reasons why:
- Complexity of neural networks: GPT models, including their hidden layers, are highly complex neural networks with millions or even billions of parameters. These parameters interact in intricate ways, making it difficult to dissect and interpret the internal operations of the hidden layers.
- Non-linearity and abstraction: Neural networks employ non-linear activation functions and complex mathematical operations. As a result, the transformations that occur within the hidden layers are often non-linear and abstract. Understanding the exact computations and reasoning behind these transformations is not straightforward.
- Distributed representations: GPT models utilize distributed representations, where each neuron or node in the hidden layers typically contributes to multiple aspects of the input data. This distributed nature of representation makes it challenging to isolate specific features or understand the contribution of individual nodes within the hidden layers.
- Lack of transparency: Deep learning models, including GPT, are often considered black boxes, meaning they provide outputs based on the input data without explicitly revealing the internal decision-making process. This lack of transparency hinders our ability to fully comprehend the operations within the hidden layers.
- Training process: GPT models are trained through a process called unsupervised learning, where they learn to predict the next word in a sequence given the context. The learning process involves adjusting the millions of parameters to optimize the model’s performance. The complex interactions within the hidden layers emerge as a result of this training process, making it difficult to directly interpret their behavior.
The GPT-3 model has 175 billion parameters with 96 transformer layers. The GPT-4 model contents are ambiguous and not published. The inner workings of the hidden layers of LLMs remain elusive, and our understanding is limited to high-level observations and interpretations of their overall performance and behavior. We are actively exploring techniques for model interpretability, but the detailed operations within the hidden layers remain a topic of ongoing research.
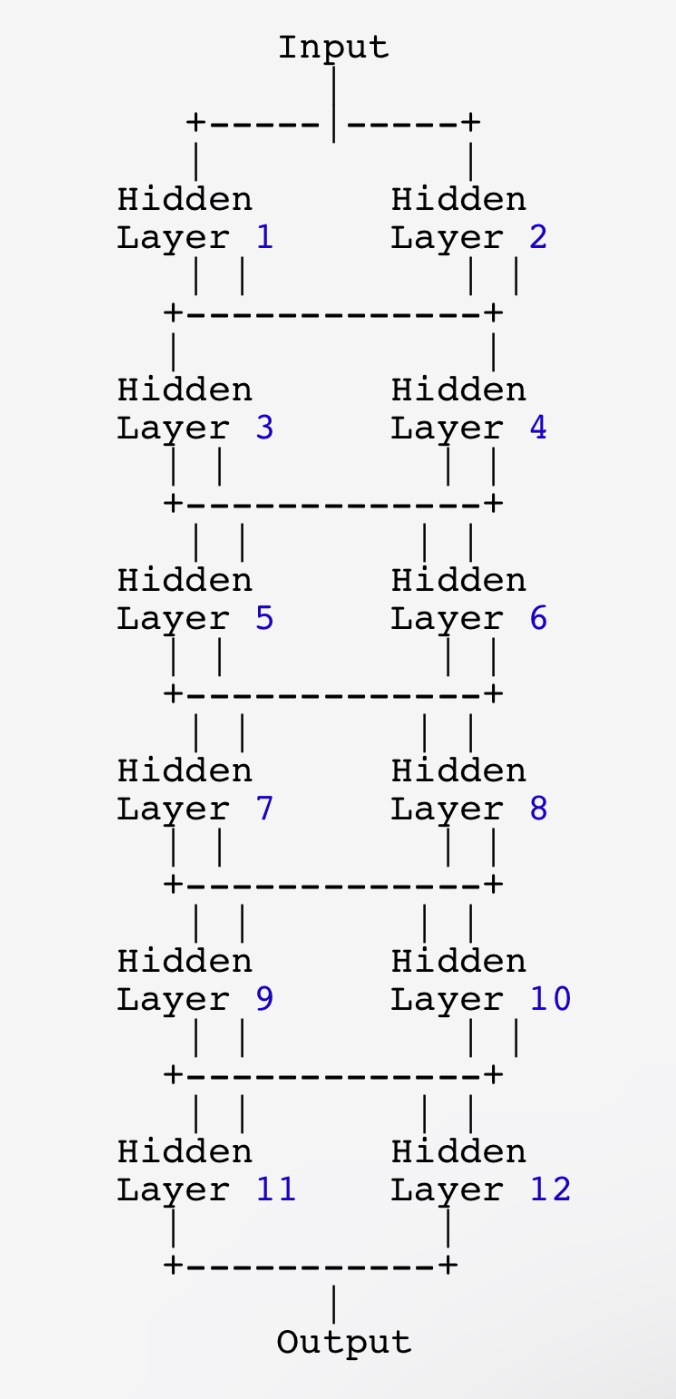
The above representation showcases an example of interconnections between the hidden layers. Each layer is connected not only to the subsequent layer but also to other layers at similar depths. These connections enable information to flow across multiple paths, facilitating richer information exchange and more complex transformations within the model. The true architecture of GPT-3 is far more intricate and involves additional elements such as multi-head attention, residual connections, and layer normalization. Nonetheless, this illustration provides a visualization of the increased interconnections between hidden layers in the model.

The Uninhabited Continent
You and I are the researchers. This is a new uninhabited continent and we are the pioneers. We have made some incredible discoveries. This is the age of the borderline frontiers and on both sides of AI, the software engineers building the models and the people that have become Prompt Engineers are both approaching the research from entirely different perspectives.
In this member only article we surface a new discovery that can allow us to see and interact with hidden layers, training data and alignments. This new discovery is not widely known and is quite powerful. We endeavor to sue this discovery for deep research into how LLMs like ChatGPT “know” what they know and improve SuperPrompts based on our findings.
If you are a member, thank you. If you are not yet a member, join us by clicking below.
🔐 Start: Exclusive Member-Only Content.
Membership status:
🔐 End: Exclusive Member-Only Content.
~—~

~—~

~—~
Subscribe ($99) or donate by Bitcoin.
Copy address: bc1qkufy0r5nttm6urw9vnm08sxval0h0r3xlf4v4x
Send your receipt to [email protected] to confirm subscription.

Stay updated: Get an email when we post new articles:
THE ENTIRETY OF THIS SITE IS UNDER COPYRIGHT. IMPORTANT: Any reproduction, copying, or redistribution, in whole or in part, is prohibited without written permission from the publisher. Information contained herein is obtained from sources believed to be reliable, but its accuracy cannot be guaranteed. We are not financial advisors, nor do we give personalized financial advice. The opinions expressed herein are those of the publisher and are subject to change without notice. It may become outdated, and there is no obligation to update any such information. Recommendations should be made only after consulting with your advisor and only after reviewing the prospectus or financial statements of any company in question. You shouldn’t make any decision based solely on what you read here. Postings here are intended for informational purposes only. The information provided here is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified healthcare provider with any questions you may have regarding a medical condition. Information here does not endorse any specific tests, products, procedures, opinions, or other information that may be mentioned on this site. Reliance on any information provided, employees, others appearing on this site at the invitation of this site, or other visitors to this site is solely at your own risk.
Copyright Notice:
All content on this website, including text, images, graphics, and other media, is the property of Read Multiplex or its respective owners and is protected by international copyright laws. We make every effort to ensure that all content used on this website is either original or used with proper permission and attribution when available.
However, if you believe that any content on this website infringes upon your copyright, please contact us immediately using our 'Reach Out' link in the menu. We will promptly remove any infringing material upon verification of your claim. Please note that we are not responsible for any copyright infringement that may occur as a result of user-generated content or third-party links on this website. Thank you for respecting our intellectual property rights.
DMCA Notices are followed entirely please contact us here: [email protected]
Brilliant.