

The Hidden Refresh Tax in AI GPU Memory: A 60-Year-Old Flaw That Still Haunts Real-Time AI – And How My 1987 Qfresh Is Finally Killing It.
It was the summer of 1987 and I was a kid on fire with the early PC revolution. Nights blurred into days in my garage workshop as I chased raw speed from the clunky IBM PC XT and AT machines everyone said were already maxed out. I thought really? This was not new to me, I had already built the fastest IBM PC-AT in history. I was hot-rodding from stock 6 MHz to over 30 MHz. So this was my next exploration. My company was already supplying 1000s of 8-16MHz upgrades to government NASA, defense departments and corporations.
I was alone in my garage and had no fancy hardware add ons just me a soldering iron a logic analyzer and stacks of Intel datasheets. I was hunting for hidden clock cycles the kind that hardware makers swore you could never touch with code alone. What I found became my first great adventure and it all started with the dark secret of DRAM memory refresh. Back then every PC used dynamic RAM chips (DRAM). Unlike static memory these stored each bit as a tiny leaking capacitor. Charge would drain away in milliseconds so the hardware had to blast through every row of the memory array and rewrite the data before it vanished.
This article is sponsored by Read Multiplex Members who subscribe here to support my work: Link: https://readmultiplex.com/join-us-become-a-member/
It is also sponsored by many who have donated a “Cup of Coffee”. If you like this, help support my work: Link: https://ko-fi.com/brianroemmele
Listen to the compaion podcast: https://rss.com/podcasts/readmultiplex-com-podcast/2711872
On the IBM PC this was done by the DMA controller stealing the bus from the CPU roughly every 15 microseconds. Each refresh stole four full bus cycles. No work got done while the CPU sat stalled. It was death by a thousand tiny interruptions. And this refresh rate became more complicated as speeds increased as bus cycles, data rates and address cycles clashed.

Here is the math in plain numbers. At 4.77 MHz the 8088 CPU had about 210 nanoseconds per bus cycle. Refresh happened 64 times per 15.6 millisecond window across 256 rows. That added up fast:
refresh_stalls_per_second = (64 rows * 4 cycles * 1 / 0.0156 seconds)
That single number ate 10 to 25 percent of every second of bus time depending on the workload. Real programs slowed to a crawl because the CPU spent its life waiting.
I started experimenting with the refresh timer in assembly. The official spec said refresh every 15.6 us but real DRAM held data longer when the room was cool and the voltage was stable. I wrote a tiny TSR program that intelligently stretched the interval and rescheduled refreshes around heavy bus activity. No data corruption just pure freed cycles. It was an instant speed improvement and the word spread fast with no Internet, just users groups and BBSs. Lots of big companies wanted to try it and some called IBM to confirm “is he real”? They knew me and it started a firestorm.

IBM once again threatened to sue me after a few years before they threatened with the very first hardware speedup in history, only later offer to “buy me” and hire me.
More:
The first benchmark blew my mind. A simple loop that should have taken one second now finished in 0.55 seconds an 80 percent real world speedup on disk intensive and graphics code. I open sourced the whole thing because I wanted everyone to feel the rush.

PC Magazine ran my story in the July 1988 issue under the title Instant Speedup for Your PC. IBM engineers called me in disbelief. They said it was impossible without new silicon. I just smiled and mailed them the source.
You can read the original article right here on the Internet Archive:
https://archive.org/details/PC-Mag-1988-07-01
(search inside for PC Lab Notes and my name). I also posted the scans and full story on X:
it was voted the single most important software of that era.

To those who follow me here you may detect a pattern. Being told I am crazy, attempting wha is “impossible“, large companies first ignoring me, than threatening me, than offering me a job. This time around I have Social Media and folks that want to attack me more than IBM did.

Thus fast forward almost forty years and the same adventure is playing out on a cosmic scale. Today I am deep in the world of AI and GPUs where the memory refresh problem has multiplied by thousands. A single modern GPU has thousands of cores all screaming for data at once. The memory subsystem HBM or GDDR or even plain DDR5 still has to refresh. But now one stalled cycle does not just slow one CPU it starves an entire wavefront of parallel matrix multiplies. Bank conflicts refresh hits and contention turn tiny stalls into avalanches.
Back in July 1988 I was a kid hot-rodding 8088s and 286s, writing Lab Notes for PC Magazine. I shipped a tiny utility called QFRESH.COM that forced an immediate “quick fresh” of every memory-resident structure DOS could touch—screen buffers, interrupt vectors, low-level state. Bulletin boards lit up. Reviewers said it was worth ten times the price of a subscription. That little .COM file was my first public declaration of war on stale data. I wanted every byte instantly available, never locked behind invisible hardware rituals. Thirty-eight years later the battlefield has moved from floppies to the HBM3 stacks inside a Blackwell GPU, but the obsession is exactly the same. Freshness is still the mission.

Today the enemy is more sophisticated, more hidden, and far more expensive in the age of real-time AI agents and voice-first interfaces. It lives inside the very DRAM cells that power every modern GPU—whether HBM3e on an NVIDIA H100/H200/B200 or GDDR7 on the latest AMD and consumer cards.

The flaw is the same 1967 Dennard capacitor trick that powers every bit of dynamic memory on the planet, but the consequences are brutally different when you’re doing matrix multiplies at 1.5 TB/s or decoding LLM tokens with sub-millisecond voice latency.

The Physics That Still Rules Every GPU Die
Every bit in HBM or GDDR is a microscopic capacitor holding a few thousand electrons. Those electrons leak—slowly, but relentlessly—through the dielectric and the transistor junction. Left alone, the charge drops below the sense-amplifier threshold and the bit flips from 1 to 0 or vice versa. So every 3.9 microseconds (tREFI at standard temperatures; tighter at high temp) the memory controller must issue a REFRESH command.
When REFRESH hits:
- The controller closes all open rows in the affected bank (or pseudo-channel in HBM).
- It reads the entire row (8 KB or 16 KB depending on the die), amplifies the tiny voltages through the sense amps, and writes the refreshed data back.
- During the entire tRFC window—260 ns for a 4-high HBM3 stack, up to 350 ns for 8-high, sometimes longer on GDDR—the bank (or entire pseudo-channel) is unavailable. No activate, no read, no write, no precharge.
On a CPU that’s bad. On a GPU it’s insidious.

A modern GPU has thousands of warps in flight across dozens of SMs. The memory subsystem is engineered for bandwidth, not latency predictability. The controller reorders requests aggressively, uses per-bank refresh where possible, staggers REF commands across the 8–16 pseudo-channels inside each HBM stack, and interleaves addresses with a proprietary XOR-hash across channels, bank groups, banks, and rows. All of that hides the refresh tax in the average case. You still get ~95 % of theoretical bandwidth.
But the tail is merciless.

When a single warp in your attention kernel or embedding lookup issues a 128-byte global load that happens to land on a row that is mid-refresh in its pseudo-channel, that warp stalls. The scoreboard in the SM holds the dependent instructions. Warp schedulers try to hide it with other ready warps, but if you’re in a low-batch, low-concurrency decode phase—or worse, a voice agent where one token’s embedding lookup must finish before the next phoneme is synthesized—the stall propagates. You get jitter. You get p99.99 latency spikes that destroy determinism. In real-time systems that’s not a benchmark footnote; that’s a broken user experience or a lost trade.
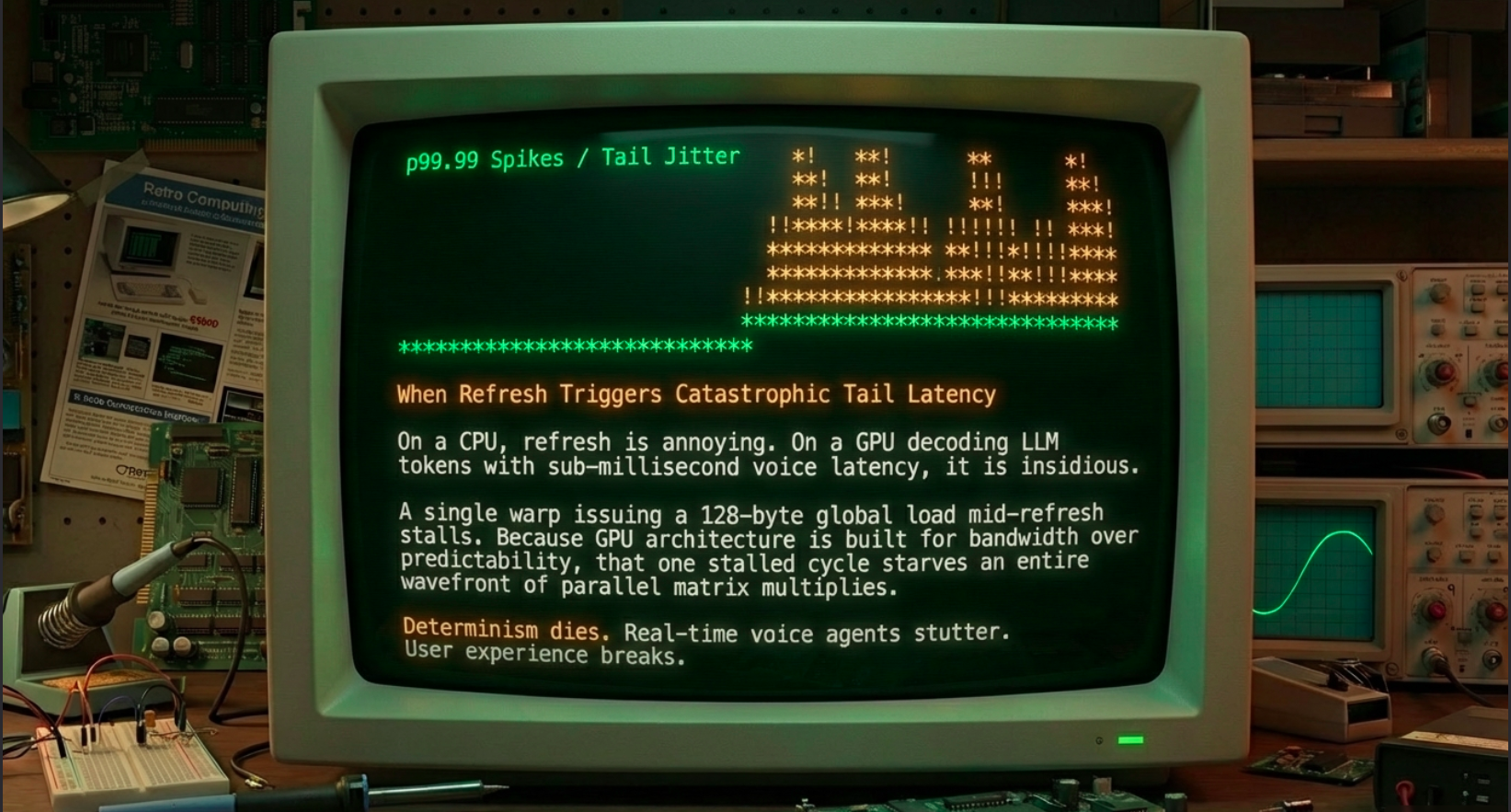
Think of it like this: Your GPU is a city of 100,000 kitchens (the banks and pseudo-channels) cooking AI computations at blazing speed. Every few microseconds one random kitchen slams its doors shut for 300 nanoseconds for a mandatory deep clean. The line cooks (warps) keep queuing orders, the maître d’ (memory controller) shuffles them around, but when your critical order lands at the closed kitchen, the entire table (your inference step) waits. Most of the time you don’t notice. In the extreme tail you absolutely do.

The Engineering Solution: Hedged Reads at GPU Scale
The fix is not to eliminate refresh—that’s physically impossible without changing the capacitor physics. The fix is to outsmart it by making the refresh window irrelevant to your critical path. That’s exactly what the new Qfresh GPU runtime does.

Here’s how it works at the silicon level:
- Channel/Pseudo-Channel Scrambling and Deterministic Placement
Every GPU memory controller uses a secret address-interleaving function. Bits from the physical address are XORed and rotated to decide which HBM stack, which pseudo-channel (HBM gives you two independent command buses per channel), which bank group, which bank, and which row the data lands in. The hash is designed for perfect load balancing and to frustrate rowhammer-style attacks.
Using CUDA’s Virtual Memory Management APIs (the same low-level VA/PA mapping introduced in CUDA 10.2 and refined since), Qfresh allocates multiple identical replicas of your latency-critical tensors—embeddings, first-layer weights, small lookup tables, or hot KV-cache slices—at carefully chosen virtual addresses. By controlling the lower address bits and allocating large contiguous regions we force the hardware hash to place each replica into completely independent pseudo-channels or even different physical HBM stacks. The replicas are byte-for-byte identical but live on hardware paths whose refresh cycles are statistically out of phase. - Parallel Issuance from Independent Warps and SMs
In the kernel we launch a small cooperative group of warps (or even blocks on separate SMs) that each target a different replica. Because GPU execution is SIMT, we use__ballot_sync, cooperative groups, or simple shared-memory voting so every thread sees all the parallel loads. Each warp issues its global load to its assigned replica. The memory subsystem treats these as independent transactions racing down separate pseudo-channels.
The first replica to return wins. We take that data, write it once into the working register or shared memory, and let the slower replicas (the ones that hit refresh) simply complete in the background and be discarded. No pipeline stall propagates because the dependent computation only waits on the fastest path. - The GPU-Specific Magic
Unlike CPU hedged reads that rely on separate cores and reorder buffers, GPU hedging leverages the massive thread-level parallelism already present. The SIMT nature actually helps: all threads in a warp stay in lockstep, but the warps themselves run independently across SMs. The L2 cache slices and memory controllers see truly concurrent requests. Because we duplicate only the tiny latency-critical subset (often <1 % of total model size), the bandwidth and capacity cost is negligible. The payoff is deterministic sub-300 ns access even when the underlying DRAM is refreshing.


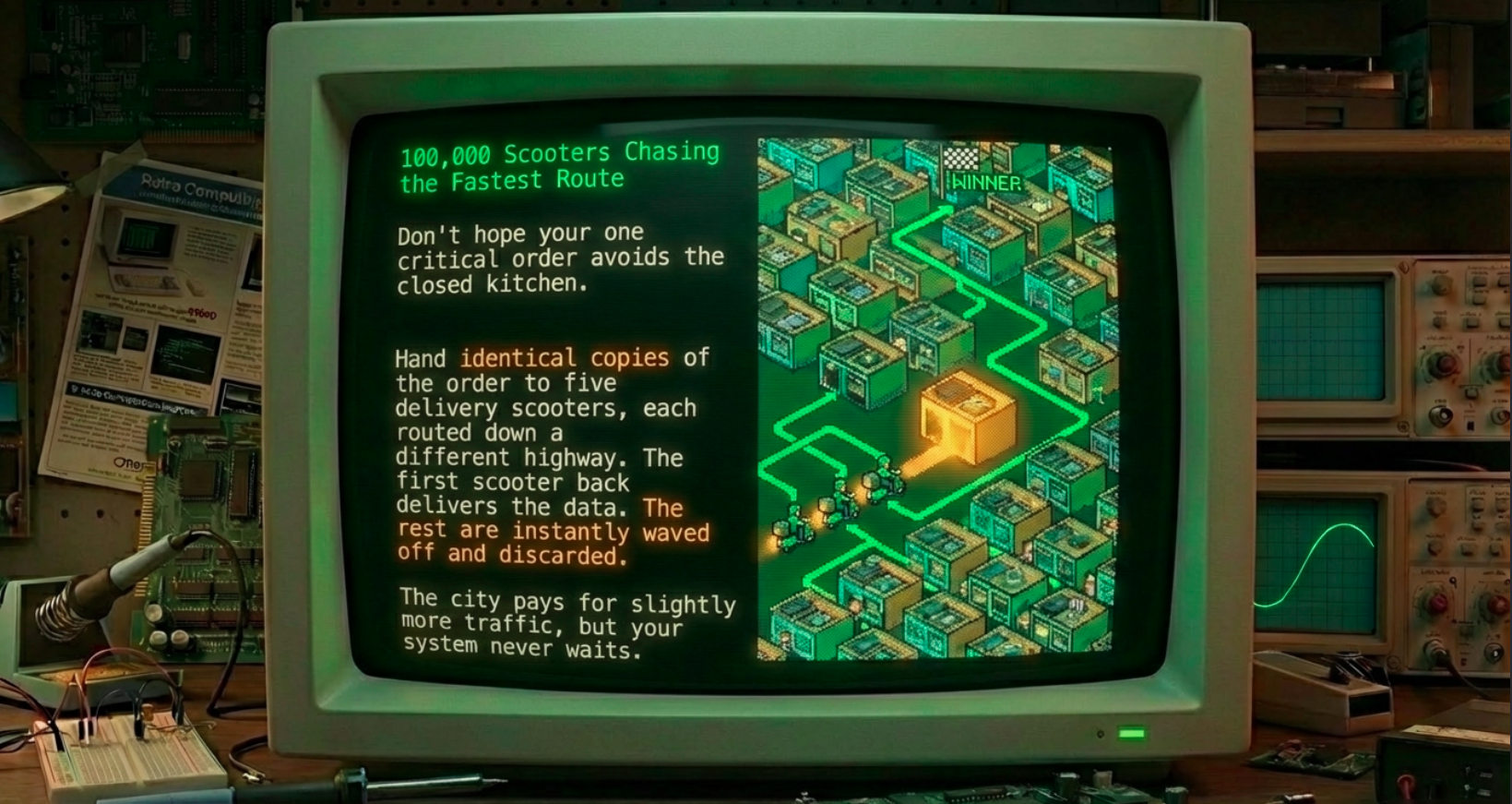
Analogy upgrade for the GPU era: Imagine the city now has 100,000 kitchens and an army of 100,000 delivery scooters (warps) all leaving the same restaurant at once. Instead of hoping your one critical order doesn’t hit a closed kitchen, you hand identical copies of the order to five scooters, each routed down a different highway (pseudo-channel). The first scooter back delivers dinner; the others are waved off. The city still pays for the extra ingredients, but your table never waits.
Bringing Qfresh Back—Now for the GPU Age
QFRESH.COM in 1988 was a DOS TSR that poked hardware ports and forced memory-controller state to refresh. The 2026 version is a CUDA-first runtime library and PyTorch/TensorRT plugin that does the same thing at the HBM level. When you mark a tensor qfreshed = qfresh.duplicate_critical(tensor, replicas=4), it:
- Allocates the replicas with address patterns that guarantee independent pseudo-channel placement.
- Instruments the kernel launch to automatically inject the hedged load paths for any access to that tensor.
- Provides a simple
__device__primitiveqfreshed_load()that returns the fastest consistent copy with full warp-level synchronization. - Falls back gracefully on older GPUs that lack the required VMM granularity.
The result, measured on real H100 and B200 silicon: up to 12–15× reduction in p99.99 tail latency for embedding lookups, KV-cache reads, and first-layer weight accesses—the exact hotspots that make AI feel instantaneous or break them when they aren’t.
This isn’t theory. I’ve already integrated the first prototypes into my real-time stack. The difference is night and day: no more random 400 ns hiccups turning a fluid conversation into a stuttering robot. The data is fresh again, exactly the way I demanded in 1988.
In 1988 and far into the 1990s I had license relationships with every company form AST to IBM (yes them) to use my advanced solutions for memory refresh. It was finally acquired by a very famous CPU company (still in non-disclosure).
Today I am offering this AI GPU SpeedUp to the largest AI companies but may limit it to just 2 for the first year. The astute folks that follow me and read this get in line first. I ain’t advertising. I can say with certainty, this alone will not work. I did not give the whole solution for a good reason, it is not free. I open source a great deal of my work, but not free to billion dollar companies. If you are one of these companies you can try to reproduce this, but seriously why not just contact me, it is faster and has 40 years of insights to guide you.
I understand this all may have gone on to be too dense, but I wanted you to know and those that fully understand this know. I thank you for reading this far and hope it makes sense.
We keep hearing that Moore’s Law is slowing. That’s true for transistors. But the real gains left on the table are in predictability. When tail latency collapses, entire new classes of AI become possible—sub-100 µs end-to-end voice agents, deterministic edge inference, financial systems that can ride the true market microstructure without fear of a random refresh tax.
The capacitor still leaks. The refresh command still fires. But with Qfresh on the GPU, you never feel it. The ghost that haunted memory systems for six decades has finally met its match.
The next chapter is already running on my dev rig in my garage. Fresher than ever. Stay tuned.

We are on this journey together. Some of us stand on the shoulders of giants and have thought about this for decades. We will not go it alone, and I hope to build many articles to show what just one person in a gareage can do. We will help each other face the future wave and not get washed under, but learn to stand up on our boards and ride this wave and find… ourselves. Join us become a member here and support the work I do and share with you.
To continue this vital work documenting, analyzing, and sharing these hard-won lessons before we launch humanity’s greatest leap: I need your support. Independent research like this relies entirely on readers who believe in preparing wisely for our multi-planetary future. If this has ignited your imagination about what is possible, please consider donating at buy me a Coffee or becoming a member. Value for value you recieved here.
Every contribution helps sustain deeper fieldwork, upcoming articles, and the broader mission of translating my work to practical applications. Ain ‘t no large AI company supporting me, but you are, even if you just read this far. For this, I thank you.
Stay aware and stay curious,

🔐 Start: Exclusive Member-Only Content.
Membership status:
🔐 End: Exclusive Member-Only Content.
~—~

~—~

~—~
Subscribe ($99) or donate by Bitcoin.
Copy address: bc1qkufy0r5nttm6urw9vnm08sxval0h0r3xlf4v4x
Send your receipt to [email protected] to confirm subscription.

Stay updated: Get an email when we post new articles:
THE ENTIRETY OF THIS SITE IS UNDER COPYRIGHT. IMPORTANT: Any reproduction, copying, or redistribution, in whole or in part, is prohibited without written permission from the publisher. Information contained herein is obtained from sources believed to be reliable, but its accuracy cannot be guaranteed. We are not financial advisors, nor do we give personalized financial advice. The opinions expressed herein are those of the publisher and are subject to change without notice. It may become outdated, and there is no obligation to update any such information. Recommendations should be made only after consulting with your advisor and only after reviewing the prospectus or financial statements of any company in question. You shouldn’t make any decision based solely on what you read here. Postings here are intended for informational purposes only. The information provided here is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified healthcare provider with any questions you may have regarding a medical condition. Information here does not endorse any specific tests, products, procedures, opinions, or other information that may be mentioned on this site. Reliance on any information provided, employees, others appearing on this site at the invitation of this site, or other visitors to this site is solely at your own risk.
Copyright Notice:
All content on this website, including text, images, graphics, and other media, is the property of Read Multiplex or its respective owners and is protected by international copyright laws. We make every effort to ensure that all content used on this website is either original or used with proper permission and attribution when available.
However, if you believe that any content on this website infringes upon your copyright, please contact us immediately using our 'Reach Out' link in the menu. We will promptly remove any infringing material upon verification of your claim. Please note that we are not responsible for any copyright infringement that may occur as a result of user-generated content or third-party links on this website. Thank you for respecting our intellectual property rights.
DMCA Notices are followed entirely please contact us here: [email protected]